
So far, many technologies have been used to deal with unstructured data, such as optical character recognition(OCR), Natural Language Processing(NLP), Machine Learning(ML), and Intelligent Document Processing(IDP). While the data stack that processes structured data is well established to a more or less satisfactory level, unstructured data has been another story altogether. LLMs present a great opportunity to have a single data stack that does not, in earnest, differentiate between structured and unstructured data.
The Structured Data Stack and the LLM Bridge
While with LLMs, we’re seeing the beginning of the removal of differentiation between structured and unstructured data, LLMs are still very slow and data today, even for relatively smaller organizations, is usually in the terabytes. Not to mention, LLMs are expensive and have much smaller context windows than data that needs to be regularly processed.
So, there’s a lot of incentive to keep building systems that can process structured data. In general, we can look at LLMs as a CPU that can process unstructured and structured data and various applications can be built on top of it, but we’re clearly in some of the earliest days. Although LLMs are very, very powerful, to use them as a CPU that can process both structured and unstructured data, I’d say LLMs are in a very nascent phase.
So, we have a data stack now that’s really good at processing structured data (hopefully). First relational databases, then SQL and then the NoSQL movements have put us in a solid position. We have SQL because computers weren’t really good at understanding human natural language. When it made its debut, the fact that SQL was English-like was a very big deal. But, even for folks dealing with SQL regularly, some of its advanced functions might mean a peek at reference material or asking their favorite LLM-powered service for help. Don’t even get me started on the various SQL dialects.
Humans are multi-modal, but so are LLMs
At Unstract, it’s no surprise that we’re big LLM fans. LLMs are changing the way we’re thinking about data, thinking about compute and scores of startups are attacking old and new problems, trying to ride a new LLM wave. Whether they’re a platform or they’re a feature, we’ll only know for sure in hindsight.
But, I believe that LLMs are a platform, but in its early days. It’s the new CPU on which a lot of software we know will be ported and new, LLM-native software further written. While I was still on the fence with regards to whether LLMs were a platform or not, what convinced me were vision models. Humans don’t do a mode switch going from images to text. They simply process whatever they’re seeing. That’s why vision models are very interesting. They process data in the same mode as humans process data as well.
The human-computer dichotomy
Until very recently, humans were creative, could process language, could make intelligent decisions, but were slow. Computers on the other hand, were several orders of magnitude faster than humans, but with numbers and some other things. They’re also very rigid in other ways. With vision models that can change. Vision models in their nascent stages, but they can remove the human-computer dichotomy. When the LLM becomes the computer, we’ll get a powerful superintelligence at our disposal. With vision models, computers will also no longer be considered rigid.
LLMs and the data stack
We’ve so far established that the current data stack is really good at processing large amounts of structured data and that LLM are good at processing unstructured data, but are slow and expensive. So, how can the current data stack then process unstructured data? The answer is already known: ETL. When the current data stack needs to deal with external data, that data first has to be brought in from the source.
To take advantage of the fact that the current data stack is really good at processing structured data all we need to do is to build a bridge between unstructured data and the current data stack. That is a bridge powered by LLMs.
There are pretty established ways to do ETL for structured data. Let’s not go into it. Even for unstructured data, like those from contracts, customer conversations, etc, ETL is the answer, but it’s not that straightforward. Let’s look at what those challenges are.
A solid ecosystem
Another thing we can’t dismiss is the solid ecosystem around the current data stack. There are ETL tools, orchestration systems, transformation systems, ad-hoc analysis systems, systems for visualizing data, etc. Not to mention just the sheer number of expert professionals available to work on all kinds of things data related. If we can then have an LLM-based system be the bridge between this ecosystem that can process and deal with structured data and all the unstructured data in the world, then it must be a good thing!
Dealing with relatively simple “unstructured data”

Unstructured data comes in many varieties. Incumbent technologies like OCR, NLP, ML, CV (Computer Vision) and IDP (Intelligent Document Processing) struggle only when the language gets very complex or when the document variants are a lot to deal with. But, where they work very well, solutions like Unstract that are LLM-native might struggle to meet cost and latency requirements. When customers are happy with results from systems that use incumbent tech, we advise them to continue using it.
LLM-native solutions like Unstract shine when document language complexity and page count are high and variants are trending towards unlimited. These are the types of documents that are generally processed by humans.
Types of unstructured data
There is all sorts of unstructured data. For instance, text from books, articles, websites, newspapers, etc. We’ve to always ask a couple of questions when dealing with unstructured data:
- Can this data be mapped to a common data schema so that a database can query it?
- Will converting this data into structured data make it useful to a broad variety of businesses?
While you can probably turn a lot of unstructured data into a queryable format, you might not find a lot of valuable use cases that a lot of businesses are having pain around and are looking to solve.
Here’s the formula to look for painful unstructured data use cases that a lot of businesses are trying to solve: Look for 2 “Vs”.
- Value: Are the use cases you are dealing with valuable? Proxies to determine if the use cases are valuable: is a human involved in processing it today? If you stop the workflow that has this type of unstructured data, will the business come to a halt?
The fact that a human is involved here in spite of this business process being critical to a business means that it’s tough to automate using current technology. Examples of such use cases are vendor contracts, legal contracts, financial documents, bills of lading, loss run reports, rent rolls, etc. - Volume: Is it a voluminous use case? If there is no volume, albeit for a valuable use case, the business won’t go through the pain of onboarding a vendor and taking the effort to automate the process. We once dealt with a boutique insurance firm.
Each deal they were working on was worth tens of millions of dollars, but they only did 3-4 deals a month. They won’t go through the pain of integrating a system like Unstract given their low volume even though they had a very high-value use case.
Is some unstructured data ETL-able?
Let’s put some use cases into a table to establish this:
| Use case | High value? | High volume? | Mappable to a schema (and thus queryable by a data stack?) | Useful for a broad set of businesses | Good candidate for unstructured data ETL? |
| Sales contracts | Yes | Yes—if you’re a SaaS vendor specializing in contracts management dealing with a lot of contracts. | Yes | Yes | Yes—for SaaS vendors |
| NDAs | Yes | Yes | Yes | Yes | Yes |
| Statements of Benefits and Coverage (insurance) | Yes | Yes | Yes | Yes for insurance | Yes |
| Invoices | Maybe | Yes | Yes | Yes | Yes |
| Bank statements | Yes—especially if you’re an organization processing mortgages / loans | Yes | Yes | Yes for financial organizations | Yes |
| Bills of lading | Yes | Yes | Yes | Yes for insurance and logistics | Yes |
| Rent rolls | Yes | Yes | Yes | Yes for real estate and financial orgs | Yes |
| News articles | Yes | Yes | No | No | No |
| Books | Yes | Yes | No | No | No |
| Web pages | Yes | Yes | No | No | No |
| Ecommerce product pages | Yes | Yes | Yes | Yes for e-commerce and e-commerce analytics companies | Yes |
The Mapping Challenge
Now, you’ve seen which types of unstructured data use cases are queryable (meaning, they can be structured and pushed into a data stack for easy querying) and which types of use cases have value and volume for broad-based businesses (meaning, there will be enough pain for them to go looking for a solution).
We’ve also established that the current data stack is good for us to process data given how good it is and also given that there is a great ecosystem around it. While I’m not saying ETL for structured data is easy (there’s a reason why ETL product companies do business worth hundreds of millions of dollars), it’s relatively easier to deal with structured data in general.
For instance, let’s take a structured data ETL pipeline that shovels data from Salesforce to Snowflake. Once an integration to Salesforce has been created, it’s not going to change in a very long time. Not until the API version that’s being used is completely deprecated.
For enterprise-grade software, you’re looking at years, if not decades of stability. Of course it’s the ETL platform that determines how it’s going to structure the data from the API to the database or data warehouse’s native format. But otherwise, with both ends being structured and the fact that there is no need to deal with a lot of variance on input side, ETL for structured sources is relatively easy.
Unlimited Variants
With unstructured data, the challenge is that there can be unlimited variants on the input side. For instance, let’s take sales contracts. If an organization gets them from 100 different vendors, it can be safely assumed that no two of them might look alike. Yet, unstructured data ETL must consistently, and accurately map them to the same JSON schema every time.
Business Logic in the Input
Seldom when dealing with unstructured documents will one have simple key/value pair extractions. Even the simplest of documents can pose challenges. For instance, invoices, though they’re seemingly simple, can have various types of complex discounts depending on the purchase type / licensing tenure of the service or goods being purchased.
Meaning, to structure or map such unstructured data to a common schema, a lot of business logic might need to be used. This only gets even more complicated when dealing with documents that deal with legal or compliance-related material, like legal agreements or summary of benefits and coverage (SBCs), etc.
Mapping with Prompt Studio
While for structured data ETL, connecting a source is as simple as choosing a connector and authenticating, dealing with unstructured data means that you’ll have to specify a mapping schema. So, a type of document (sales contracts, NDAs, bank statements, etc) will map to a specific schema. Schema mapping is a very deliberate process. If you don’t set a proper singular schema, you can’t process the data downstream with your data stack.
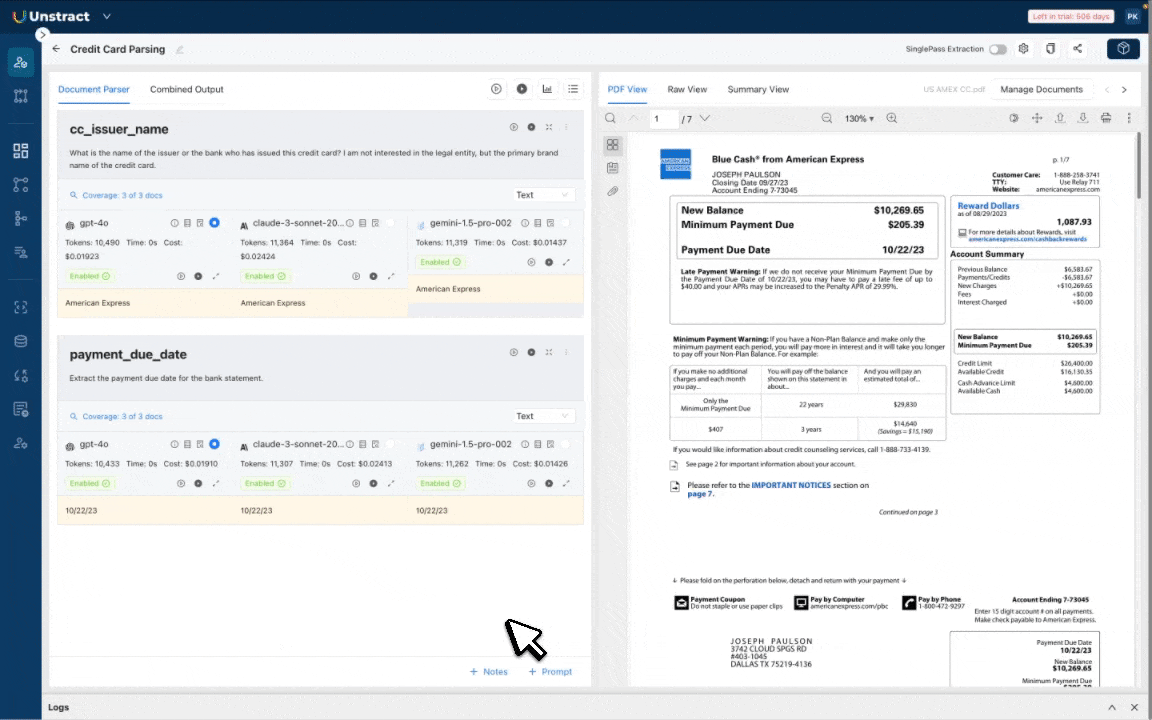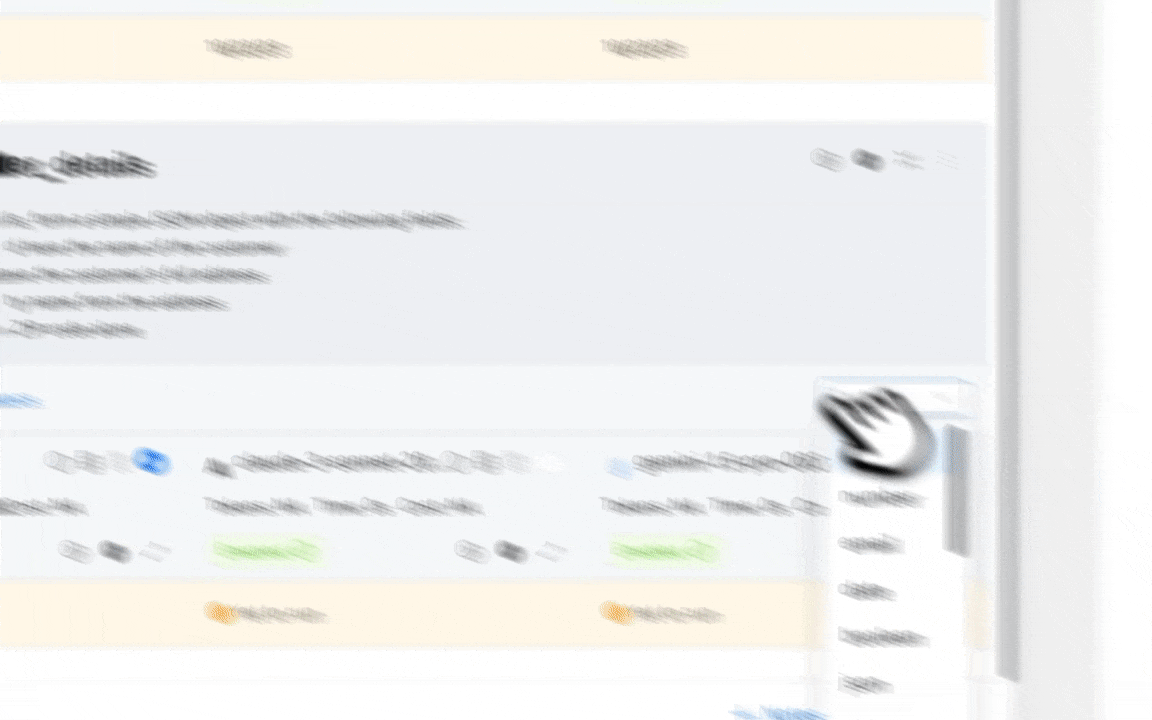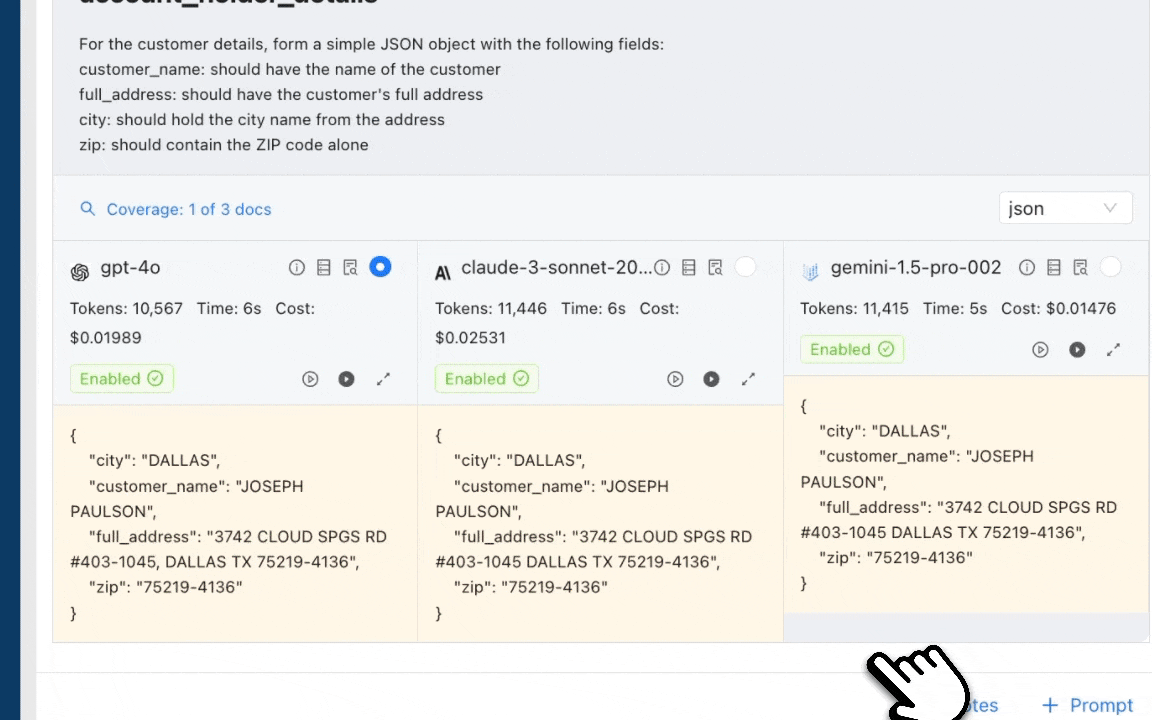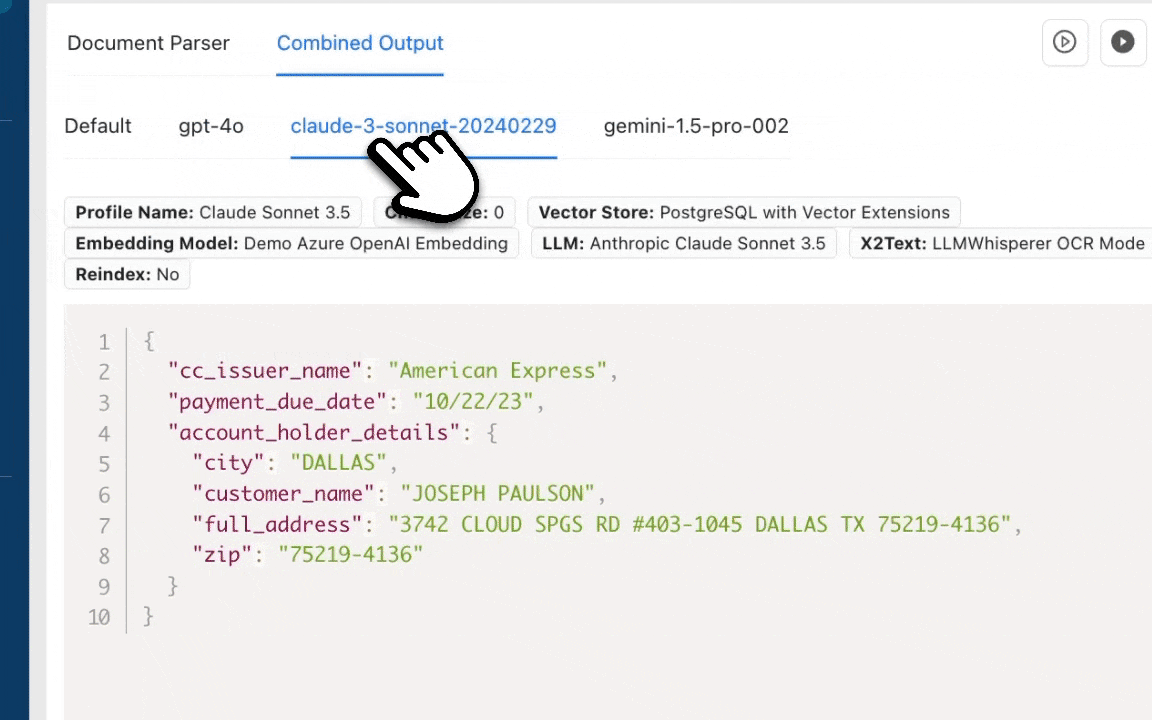
This is the reason why with Unstract, we created Prompt Studio, a purpose-built schema mapping environment. With Prompt Studio, users can provide a representative sample of document variants (10-15 usually) and do the mapping with prompt engineering. While this is something that can be done in a traditional programming IDE, Prompt Studio offers the following features that make it easy for developers to do the schema mapping.
- The Prompt Coverage feature lets you see the field value being extracted from each variant for any particular prompt.
- Output Analyzer lets you see the document variant and the output in the combined schema side-by-side.
- You can enable features like LLMChallenge where 2 LLMs are used to give you accurate outputs to see how well the extraction actually happens.
- You can also enable cost-saving features like SinglePass Extraction and Summarized Extraction while ensuring extraction quality is not taking a hit.
- Compare the quality and the cost of extraction for multiple LLMs side-by-side
- Debug your LLM extraction with source document highlighting (we show you from where the LLM actually pulled out the data in a document)
But, I can do the mapping with ChatGPT easily!
You should be able to get a mapping for any document you upload to JSON. Trouble is that every time you ask, you’re going to get a different schema. Like we discussed in an earlier section, the JSON schema mapping is a very deliberate process. You want to establish a single schema so that you know how to process it (transformation, enrichment, visualization, etc) downstream using your existing data stack.
You can even supply a schema and most LLMs will map it for you, but remember that:
- Many of these documents will have a lot of business logic to deal with when extracting many fields
- As the number of variants increase, your prompts will need to become more and more generic
As you start facing these challenges, you’ll find more and more that you’ll be way more productive in an environment that is purpose-built for schema mapping for documents that can have unlimited variants. A consumer-facing product like the ChatGPT UI or even a traditional programming IDE will never be as productive as Prompt Studio for schema mapping.
As LLMs get smarter, Unstract won’t be needed!
Just like how programmers need to tell computers every single step they need to take, when automating work that is currently done by humans, your instructions to the LLM for mapping complex documents into a single JSON schema need to be very comprehensive. In some of the more complex projects we’re involved in, it is not uncommon for us to write prompts that are hundreds of lines long.
Remember that we’re automating workflows in which usually, highly skilled humans many times having decades of experience are involved. When you structure / map these documents to a common JSON schema, you’ll need to include all the knowledge that the human was using to remove any ambiguity. As the number of possible variants of the document increases, the mapping gets harder and harder. Let’s review the challenges:
- No matter how smart LLMs get, you’ll need to transfer a lot of vertical expertise that a human had previously to make a successful mapping. For this an environment like Prompt Studio is way more productive compared to other ways of arriving at the mapping.
- Source Document Highlighting means that you can debug LLM ambiguity and accuracy issues way more efficiently.
- Businesses are always looking for the cheapest model that is the most accurate for their use case. Prompt Studio lets them compare models side-by-side for cost and accuracy.
- LLMs, even the latest ones, continue to hallucinate. This is a big problem for data mapping. This is where features like LLMChallenge come in. You either get the right extraction or no extraction at all. Our philosophy is that a null value is better than a wrong value. Wrong values undermine trust in the system.
- LLMs can get really expensive really soon. This is where features like SummarizedExtraction and SinglePass Extraction come into play.
- Remember that at the end of the day, LLMs are just APIs. You’ll need a system in place that uses LLMs to actually define the mapping consistently and accurately while also providing ways to read the unstructured data, process it and write it to a destination database or data warehouse.
- While doing all this, the system has to provide ways to version and manage prompts for long-term use. Prompts are the new programming language
OCR vs. Mapping vs. ETL
Now that we’ve understood a lot of background on the ability to process unstructured data, let’s look at the stack that makes it possible.
The real-world nature of processing unstructured documents
When we started building Unstract, there was no one for us to “get inspired” (translation: copy) from. As we’ve built out the stack, and gone to market, we’ve pulled out, gone back to the drawing board, solved various hard problems and went to the market again. Let’s look at some of these challenges.
| Issue | Challenge | What we built |
| Forms and documents with multi-column layouts, tables | If the layout is not preserved carefully before the raw text is sent to an LLM, many multi-column documents and forms will completely lose their meaning | We built Layout Preservation mode in LLMWhisperer, our raw text extraction service to provide as much context as possible to the LLM |
| Checkboxes and Radio Buttons | There are clean ones and not-so-clean ones that are hand checked. We’ve to read them all. | We trained a Machine Learning model on ~300k annotated samples. This model can output the text “[]” and “[x]” for unchecked and checked radiobuttons and checkboxes respectively. |
| Off-orientation scans | Scans can be off by any degree. | We detect and correct this in the extraction. |
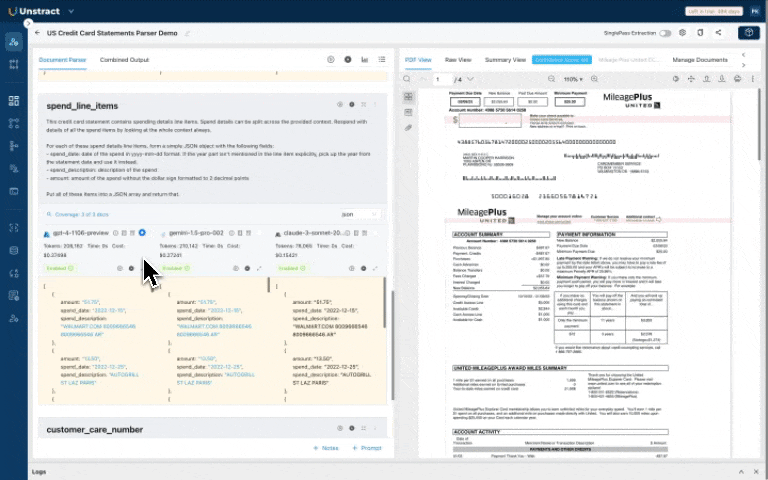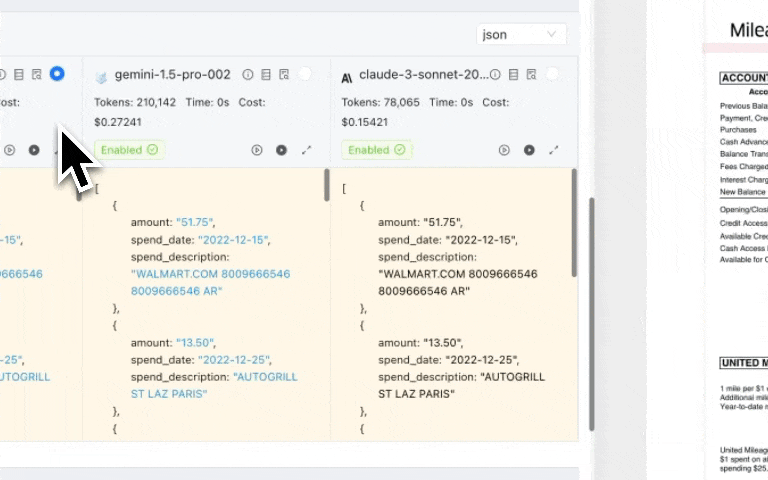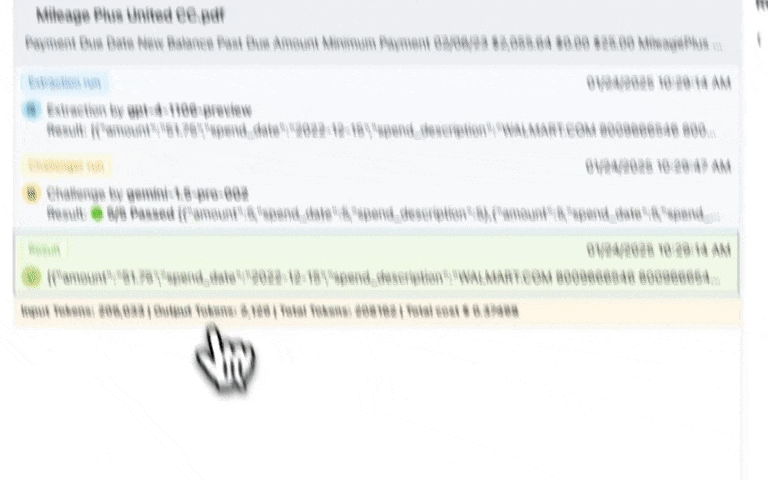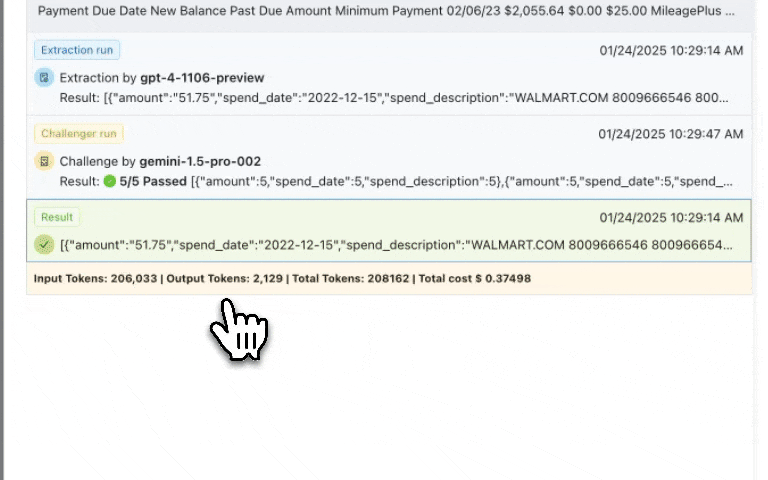
| LLM Hallucinations | This means that extractions can be plain wrong and we won’t know about it. In other words, there is no way to programmatically detect hallucinations. | We built LLMChallenge to either get the right extraction or no extraction at all. It is an LLM-as-a-judge implementation. |
| Escalating LLM Costs | At scale, these costs can add up, making many projects unviable. | We built SinglePass Extraction and Summarized Extraction. These features save LLM tokens from 5-10x! |
| Extraction Ambiguity | When a document type has a lot of variants, LLM field extractions can get ambiguous. | We build source document highlighting that shows from where in the source document the LLM is pulling out the extraction from, making debugging very efficient. |
| Human-In-The-Loop Efficiency | When reviewers review field extractions, especially when documents are long, it’s not easy to locate the area from where the extraction happened for verification. | Source Document Highlighting means that the portions of the document from where the LLM actually got the data is highlighted and scrolled to. |
| Classification before Extraction | In many workflows we automate, customers get a packet of various documents. Before calling an API to extract or pushing it to the right folder for unstructured data ETL, they need to classify the documents. | We built Task Pipelines in Unstract for this and other purposes. |
| Defining mapping for unlimited variants | For many use cases, the same document might have almost unlimited variants. Prompts need to consider nuances and extract fields as generically as possible. It’s like explaining to a human how to broadly process various variants. | We built features like Prompt Coverage and Output Analyzer and Source Document Highlighting to take care of this. |
| Ensure customer’s data doesn’t leave the cloud in which they operate | Customers only recently opened up to using LLMs in the first place. They needed to make sure data did not leave their cloud. | We built support for models in all the 3 hyperscalers: Bedrock for AWS, Vertex AI for GCP and Azure OpenAI on Azure. |
| Efficiently choose the best LLM for the mapping at hand | Customers need to choose the cheapest model that is performing the best | When doing the mapping, customers can compare LLM accuracy and costs side-by-side in Prompt Studio |
| LLM context window size issues | Dealing with documents that are too long to fit into the output context window size of the LLM is easy. It can be fixed with RAG techniques. The real challenge comes when the output (too many fields being extracted) won’t fit into the output context window size of LLMs. | We build proprietary solutions to make multiple calls and then combine the data seamlessly. |
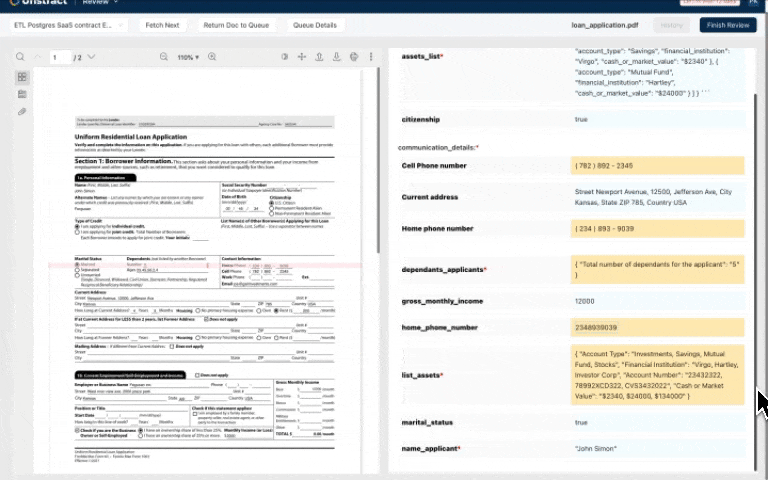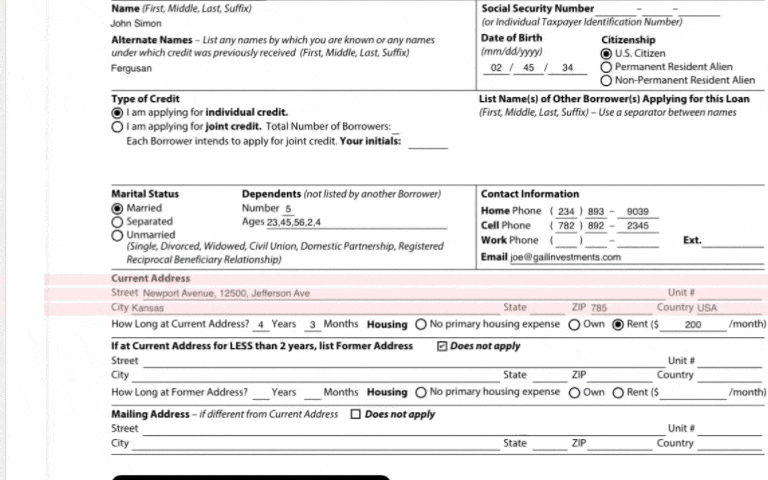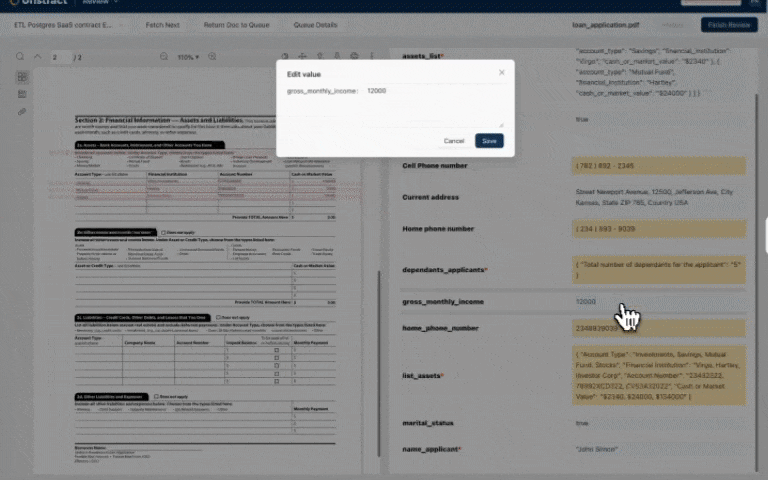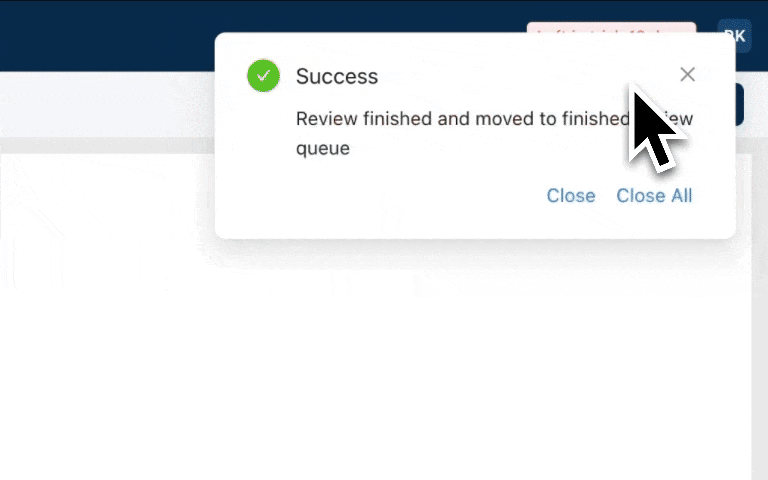
Human-in-the-loop(HITL): Source Document Highlighting shows where extracted data came from in the original document.
The Tech Stack

What’s a True Unstructured Data ETL Platform?
This is pretty straightforward to answer:
- Users should be able to bring any document with unlimited variants and get the schema mapping done accurately and consistently (development time) in a reasonable amount of time.
- They should be able to use all the popular sources and destinations (cloud file systems and databases / data warehouses) so that unstructured documents can be read from these folders, the data structured and be written to the destination.
- The system should be able to process realworld documents (language complexity, unlimited variations, handwritten text, forms with checkboxes and radiobuttons, etc).
- The system should have mechanisms for high accuracy and lowering costs.
- The system should enable humans in the loop efficiently due to legal reasons or due to reasons of very poor input data (fax copies, doctor’s written notes, etc)
You can see how the Unstract stack depicted above is built to provide these attributes.
The (Future) Effect of Vision Models
We have established that unstructured to unstructured data mapping is a very valuable application for LLMs and that the actual mapping will be required for use cases that involve complex workflows. We do believe that as vision models get better and better raw text extraction services like LLMWhisperer, etc might not be needed.
Future Vision Models should be able to directly do the mapping from the user’s prompts without first requiring the raw text to be extracted. They should expressly be able to read handwritten text, interpret checkboxes and radiobuttons, tables, multi-column documents and forms and even interpret charts of various types.
Concluding Thoughts
While there are a bunch of incumbent techniques that let us deal with unstructured data, albeit with or varying complexity, it is important to understand the viability of such projects, especially when operating at scale. Unstructured data complexity is a wide-ranging spectrum and at the lower end of it, incumbent techniques work really well with very high accuracy and low cost, making it difficult for LLMs to compete with them at the current costs and latencies.
But, for workflows in which humans are required due to the complexity and the unlimited variance in the data, LLMs provide a powerful opportunity for automation with workflow and agentic systems. For such use cases, viability is present since complex, manual work is being automated and humans are being freed (who are otherwise more expensive than the cost of operating the solution and the LLMs).






















