

Unstract is a no-code LLM platform that lets you automate even the most complex workflows involving unstructured data, saving you time, money, and scaling headaches. Boost efficiency, eliminate errors, remove manual intervention, and unlock new possibilities — all leveraging the power of AI.
What does Unstract help solve?
Many organisations struggle with processing data stored in disparate document sources that are in multiple formats. Presently, this is solved by human-in-the-loop manual data extraction or, in some cases, by inflexible, templatised legacy OCR systems.
The challenges
When humans are involved, errors can be introduced, and processes that should take minutes are prolonged to days or weeks, hindering efficiency and delaying decision-making.

What does Unstract do?
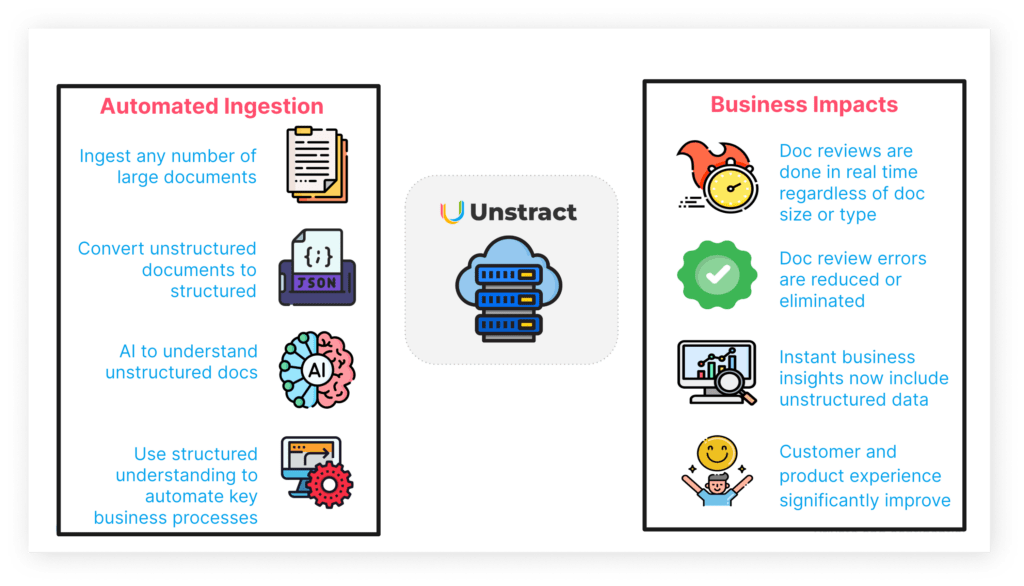
Unstract is an AI-powered document processing automation system that works with unstructured documents of any format, type, and design. The extracted data can be consumed in multiple formats: spreadsheets, JSON, a table in a database, or sent to your system with an API.
The essential functions include:
- Document classification
- Data extraction
- Data validation
- ETL pipelines for unstructured documents
- Data integration
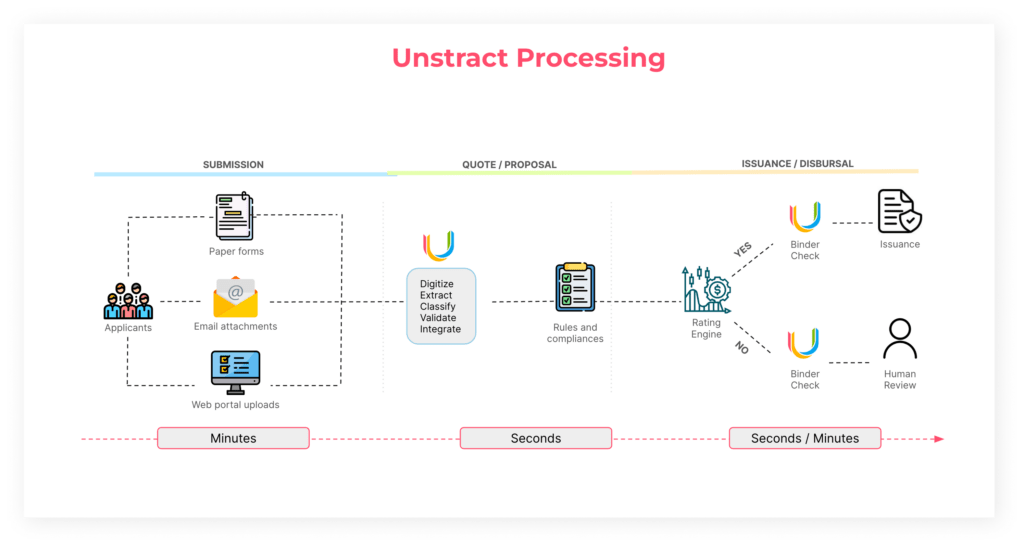
Consider the insurance underwriting process: This involves underwriters manually reviewing KYC document submissions, processing contracts, and extracting data from claims forms.
Unstract streamlines this process by ingesting large documents and converting them from unstructured to structured formats, enabling rapid review, analysis, and processing.
Leveraging large language models for reasoning capabilities, Unstract automates the entire document workflow end to end, reducing document review times from days to minutes.
How exactly does Unstract solve document processing challenges?
The following are the critical building blocks of Unstract, which help enterprises readily and confidently adopt AI into their processes.
Flexible document ingestion
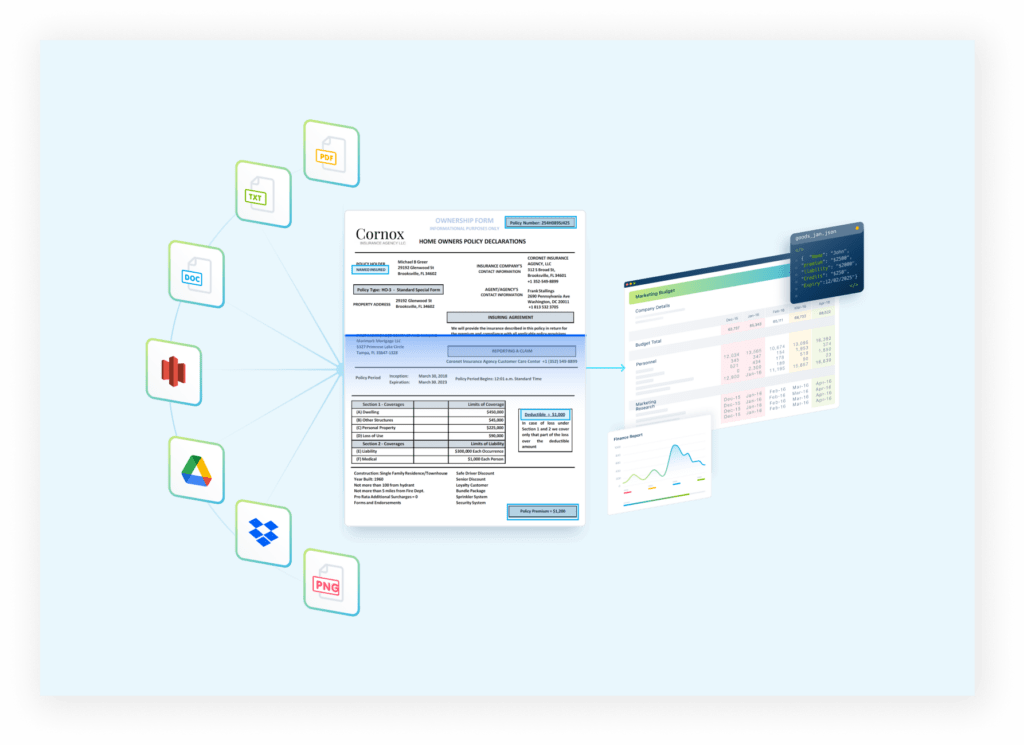
Ingest data from any source or even multiple sources—Dropbox, S3 Object Storage, data lakes, and more. Handle large volumes of documents of any format, form, and type seamlessly. Scaling processes and flexibly handling any document use case should never be your problem anymore.
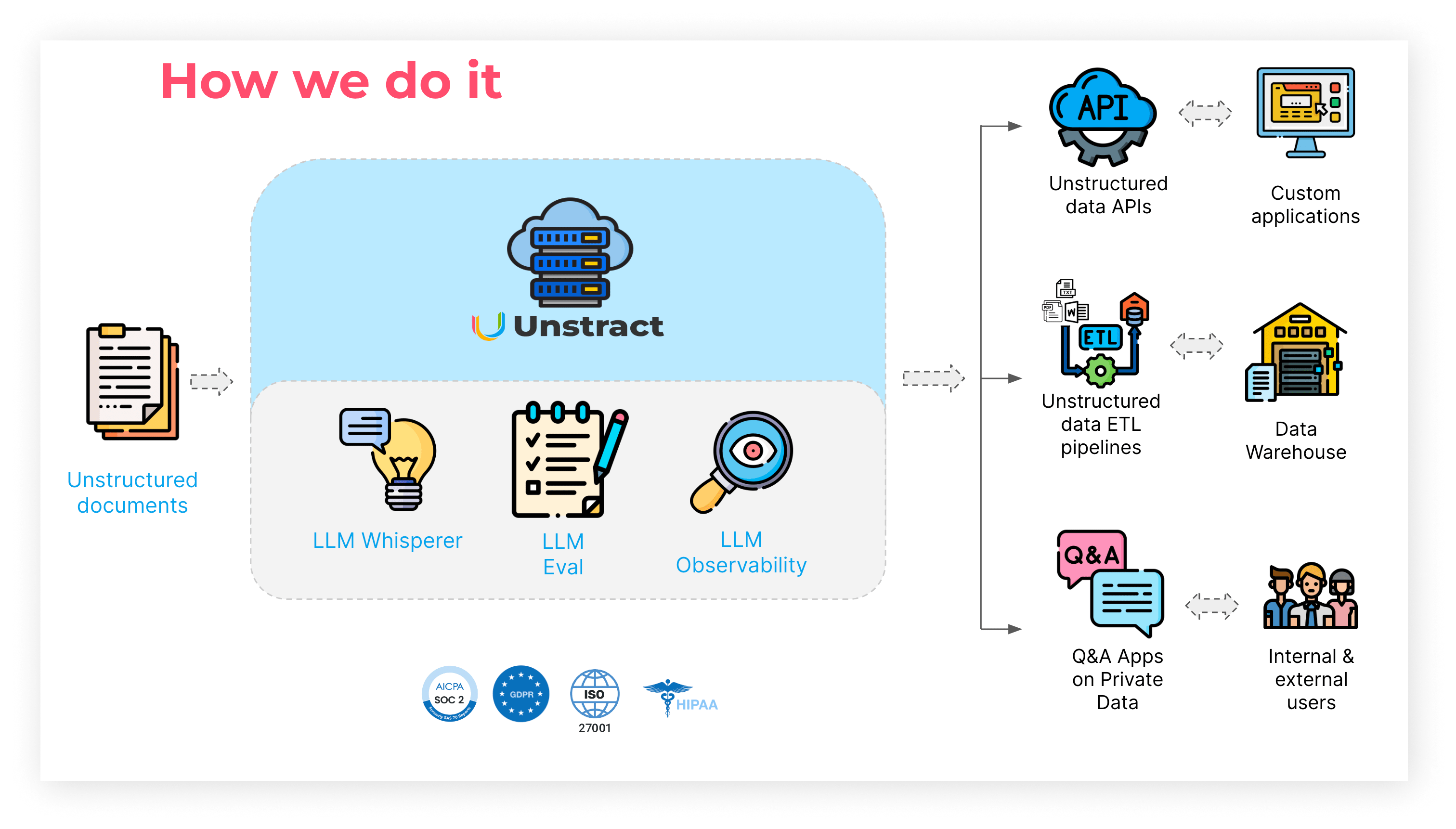
LLMWhisperer
LLMs are powerful, but their output is as good as the input you provide.
Documents can be a mess: widely varying formats and encodings, scans of images, numbered sections, and complex tables. Extracting data from these documents and blindly feeding them to LLMs is not a good recipe for reliable results.
LLMWhisperer is a technology that presents data from complex documents to LLMs in a way that they can best understand.

LLMEval
LLMs can have human-level language understanding and reasoning capabilities. But the trouble is when they’re wrong, they can be wrong. Hallucinations and just plain wrong results mean you need to double-check all output. You might as well do things manually.
LLMEval lets you trust output from LLMs by using two LLMs in a maker-checker configuration with varying contexts, creating a confidence score for all output and bifurcating results confidently for consumption or sending them to a review queue.
LLMObservability
Given their probabilistic and non-deterministic nature, large language models need a new set of metrics and observability systems. Unstract allows you to peer into how your data and LLMs interact during the build phase of your projects and, more importantly, while running projects in production.
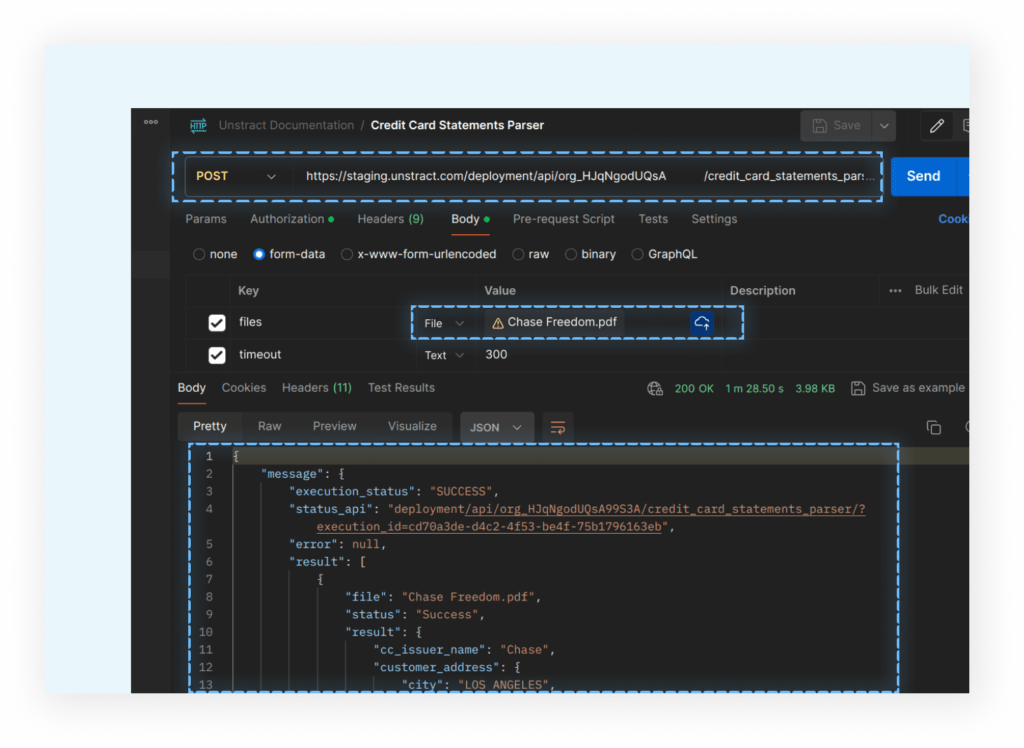
Multiple format data extraction
In goes unstructured documents, and out comes beautifully structured JSON or a downloadable spreadsheet file format. The extracted data can be readily consumed across custom applications, stored in data warehouses or sent to your reporting and analytics tools.
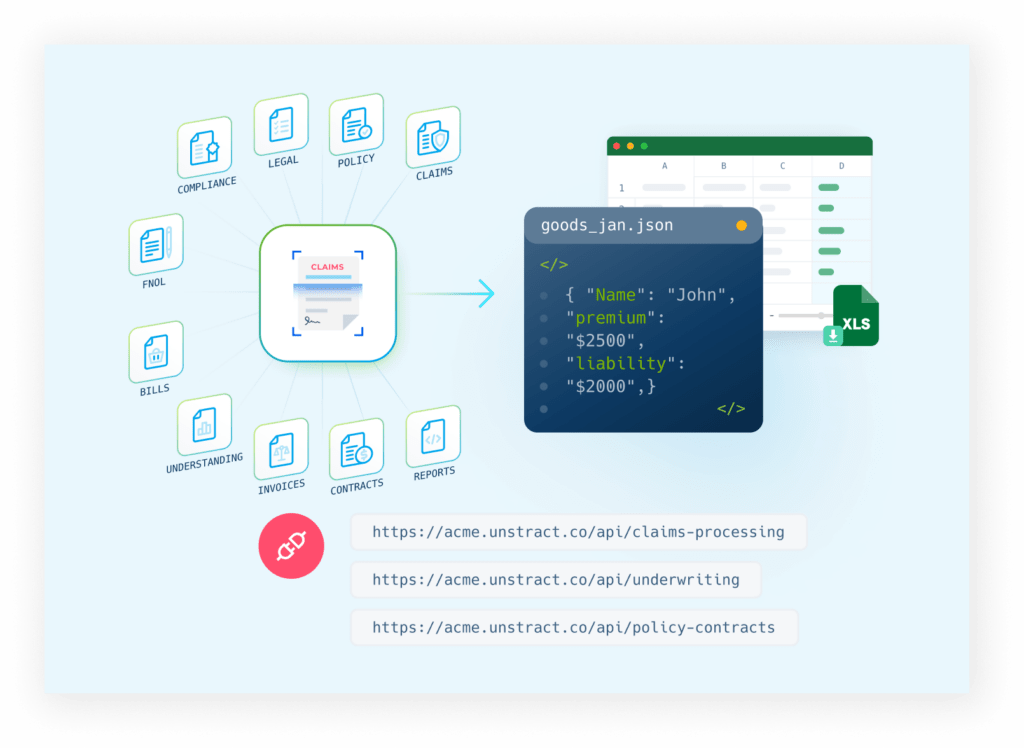
Automation Hub
For a wide variety of common documents, the Unstract API Hub is a repository of powerful APIs that can structure data from unstructured documents.
You don’t have to worry about LLMs, Embedding Models, Vector Databases, information extraction (complex encoding schemes, tables), infrastructure, security, or scalability.
While the Unstract API Hub supports the most common document types, you might want to automate workflows that involve document types that are not yet supported.
All you need to do is use our no-code Prompt Studio to add support for your new document type and then create a new API Deployment that uses your project.
Key benefits
- Achieve a remarkable 60% increase in document processing speed.
- Experience a significant 30% reduction in operational costs.
- Reduce cycle time and prevent the likelihood of increased risks and potential errors in decision-making.
- Reducing human-in-loop touch points helps minimise delays and results in faster customer complaint resolution.
- Unstract helps ensure that the extracted data adheres to established compliance standards and legal requirements.
- Extracting relevant data that is always trustworthy and predictable helps your team make confident decisions.
Business use cases
Insurance
Unstract improves operational efficiency by automating critical insurance workflows in claims processing and underwriting. It also enables high-accuracy critical data retrieval, enabling insurers to make faster underwriting decisions at scale.
- Insurance claims processing
- Insurance underwriting
- Straight-through processing
- Insurance triaging
- Processing loss run reports
Financial services
Reduce turnaround times and improve document processing accuracy for a faster and more efficient mortgage approvals and credit decision-making process.
- Mortgage origination
- Customer Onboarding(KYC processing)
- Consumer and corporate lending
- Credit decisioning
Secure and compliant
Unstract adheres to the strict rules and regulations of various compliance authorities. Unstract is SOC2, ISO, GDPR, and HIPAA compliant.

What’s next?
If you are looking for modern solutions to automate your document processing workflows at your organisation, do schedule a call with us. We’ll help you understand how Unstract leverages AI to solve document processing automation and how it differs from traditional OCR, and RPA solutions.



