
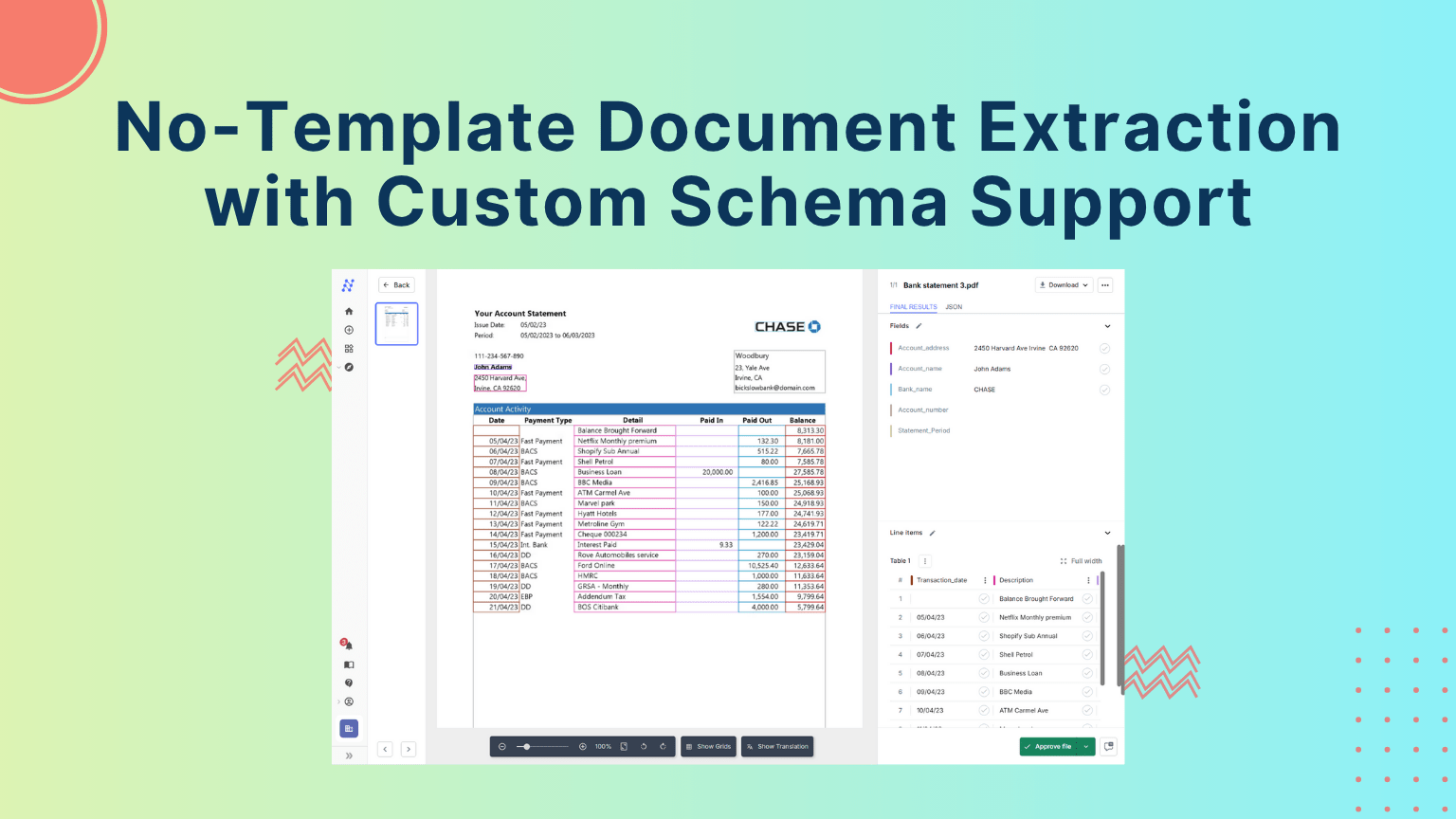
Document Processing: An Introduction
For more than two decades, document processing has been held back by the same bottleneck: manual templates. Whether it’s invoices, bank statements, property inspection reports, or legal contracts, most systems still expect users to draw boxes, define rules, and endlessly adjust layouts just to extract data.
This approach worked in an earlier era of OCR and automation, but today it has become a costly burden. Businesses spend countless hours reconfiguring extraction logic every time a document design changes. Worse, when formats vary widely, as they do in finance, insurance, or real estate, template-driven tools collapse under the weight of constant manual upkeep.
Yet, organizations don’t just need faster data capture. They need flexibility. Pre-built extractors can pull standard fields like invoice totals or dates, but few businesses live in a “standard” world. Custom requirements, like unique identifiers, industry-specific terms, or regulatory data points, rarely fit into rigid defaults. The result? A mismatch between what the tools deliver and what the business actually needs.
The solution is here: AI-driven, template-free document processing with customizable schemas. Instead of wasting time on fragile templates or fixed field sets, modern systems allow businesses to define exactly what they want extracted, no matter the layout, no matter the format. With schema-first AI, organizations can finally unlock truly intelligent document processing.
The Legacy Problem in Document Extraction: Manual Templates
For decades, document processing systems have relied on templates and rules to extract information. The process started with basic Optical Character Recognition (OCR), which could scan a page and turn printed text into machine-readable characters. While revolutionary at the time, OCR provided little structure – organizations could capture raw text, but not meaningful fields like “Invoice Number” or “Transaction Date.”
To solve this, vendors introduced rule-based templates. Users could upload a sample document, highlight the relevant data, and “teach” the system where specific fields were located. Over time, semi-automation emerged, allowing systems to reuse those templates across batches of similar documents. But at the core, the approach has remained the same: draw bounding boxes, define extraction rules, repeat for every format.
Legacy System A
Imagine uploading a bank statement into what we’ll call Legacy System A. The interface prompts you to manually highlight fields like Account Number, Balance, or Transaction Date. Each highlight creates a bounding box, and behind the scenes, the system associates that box with an extraction rule.
Here, we defined rules for the Issue Date, Period, Name, Address, and Activity:
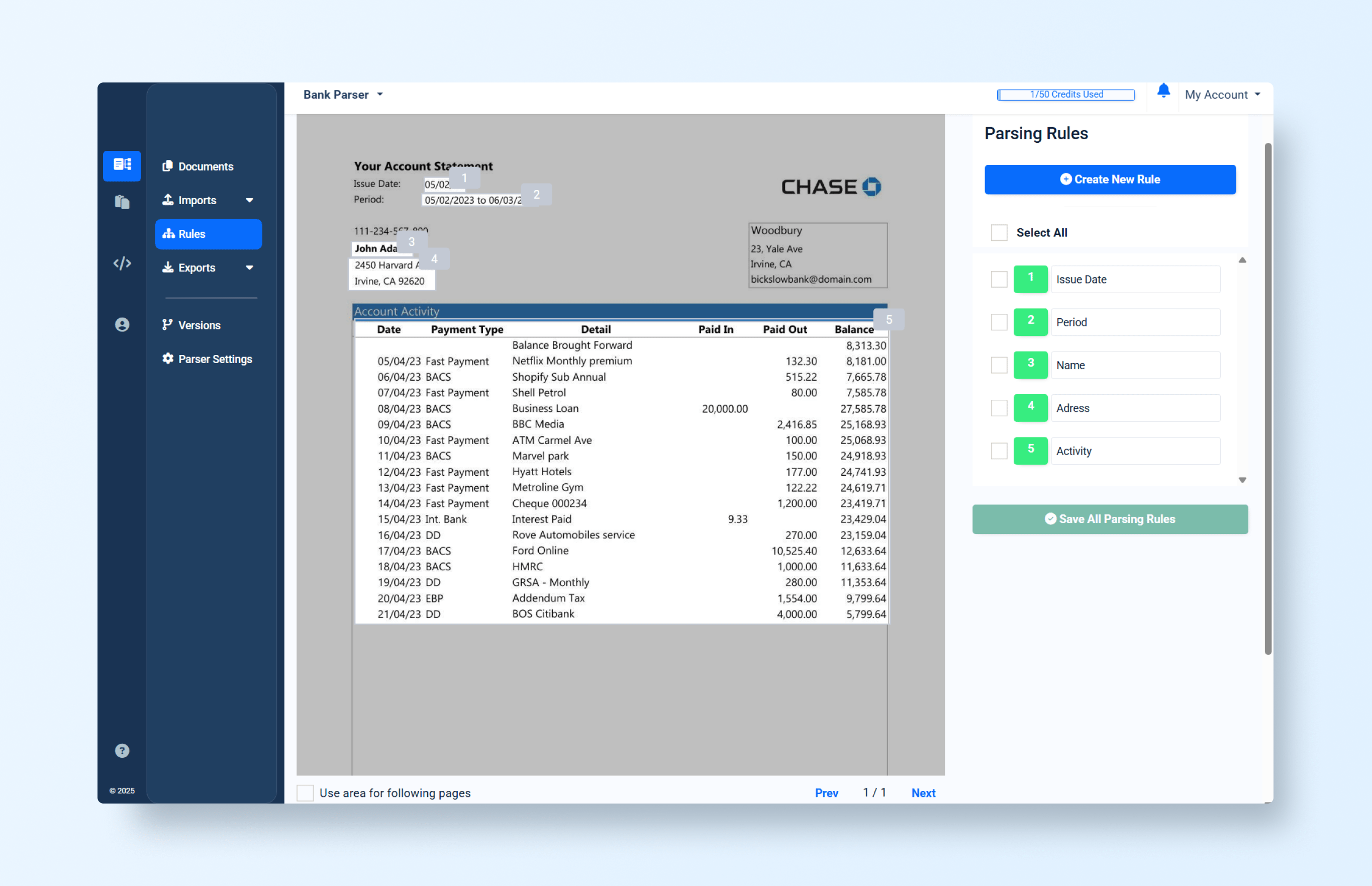
It works, but:
- All extraction rules were defined manually.
- While they can extract the corresponding text, the approach quickly becomes fragile.
- If the Address field suddenly includes three lines or fields, the system fails to adapt.
- You could try to fix it by using anchors and estimating possible field sizes.
- However, this method is not scalable or maintainable in the long run.
Let’s also try to process the table with the account movements:
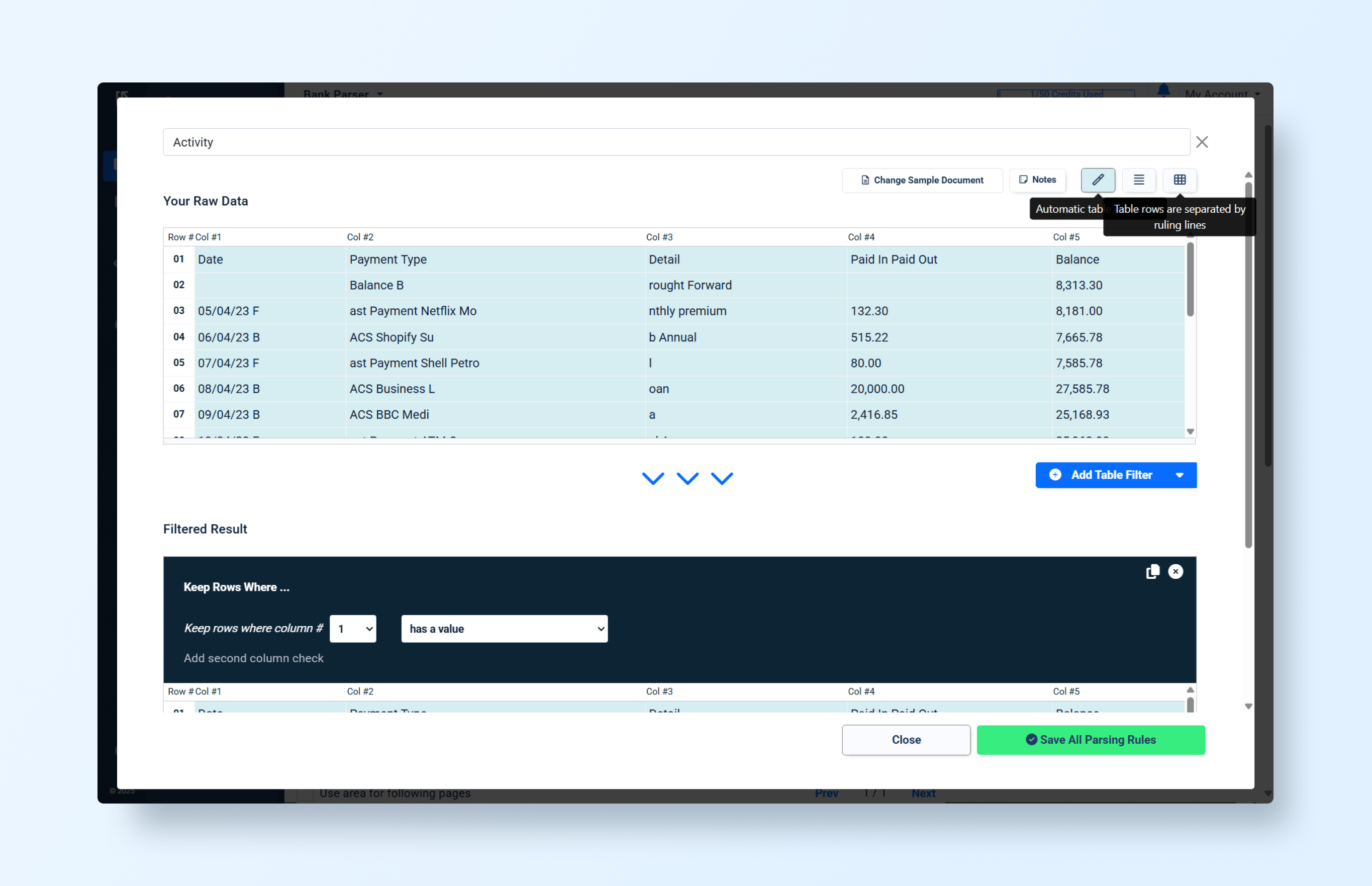
The system helps with defining a table, but:
- Initial column definitions were incorrect.
- This required manual adjustments to fix.
- We were unable to define (or assign) column names.
- As a result, the extraction/mapping process became error-prone and slow.
Let’s adjust the columns:
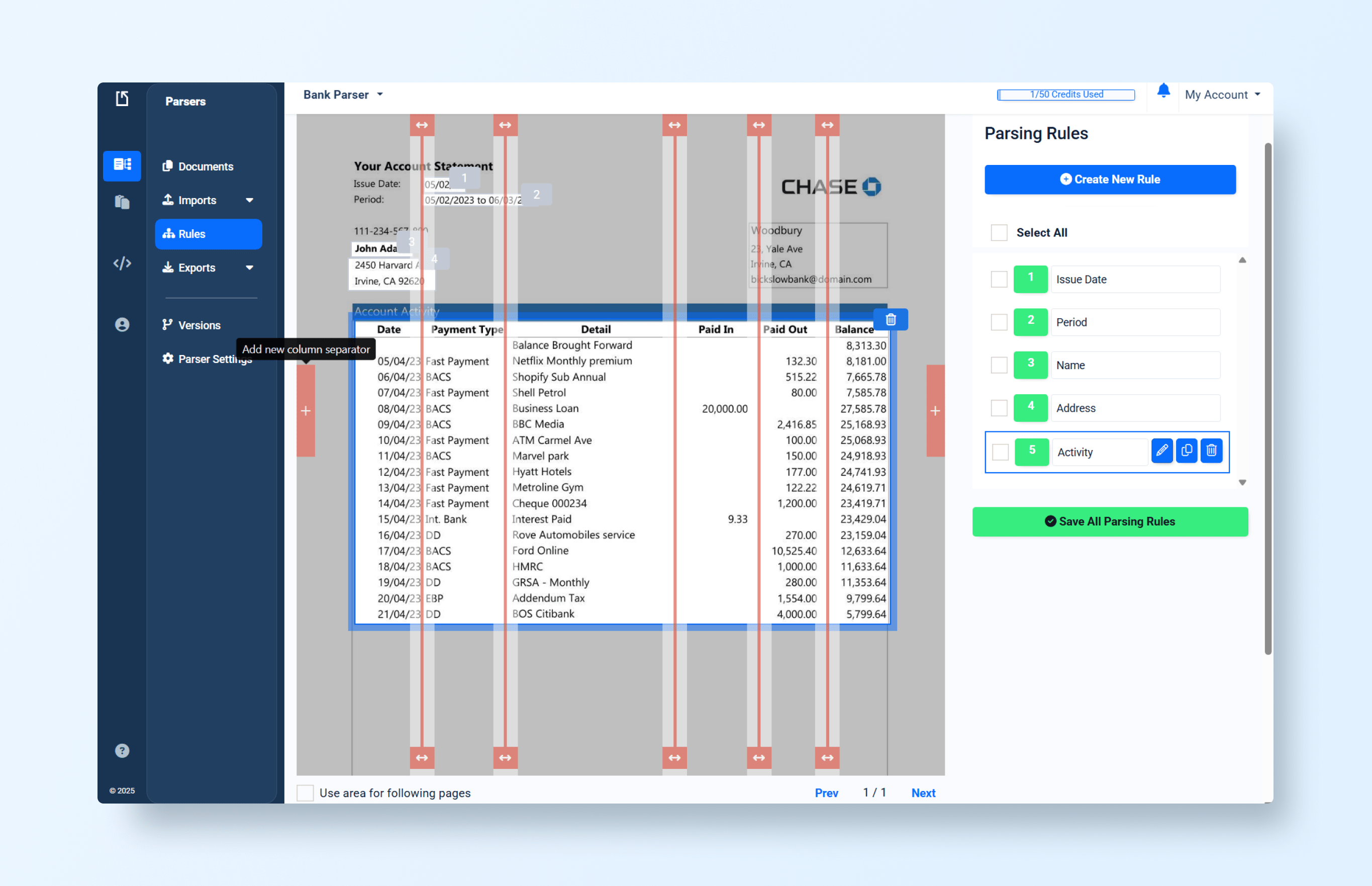
We improved the extraction, but:
- All columns had to be manually defined based on spacing.
- The column sizes could change between documents.
- The full table length is often unknown.
- These variations can cause frequent alignment and extraction issues.
Legacy System B
Now take Legacy System B – a more advanced, automated extractor. It begins by scanning the document and then pre-defines a set of extraction rules for known patterns such as headers, labels, or key-value pairs.
Initial mapping is promising:
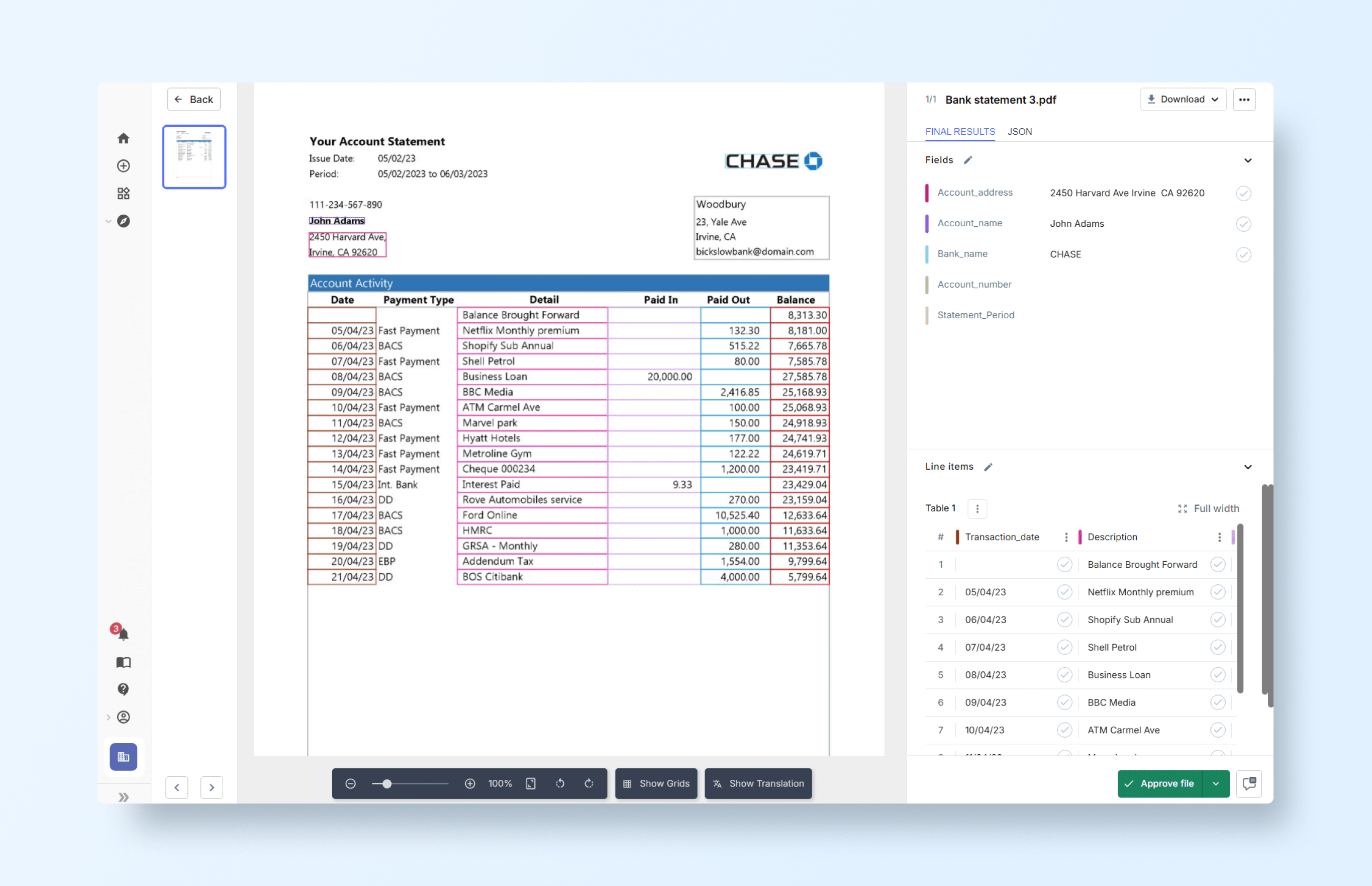
But even though it seems more advanced, it still struggled with accuracy:
- It correctly detected the statement period field but failed to map its actual area in the document.
- It assumed an account number field that didn’t exist in the document.
- The table structure was defined incorrectly, skipping one of the columns entirely.
- These errors highlight how rule-based systems often misinterpret context when layouts vary.
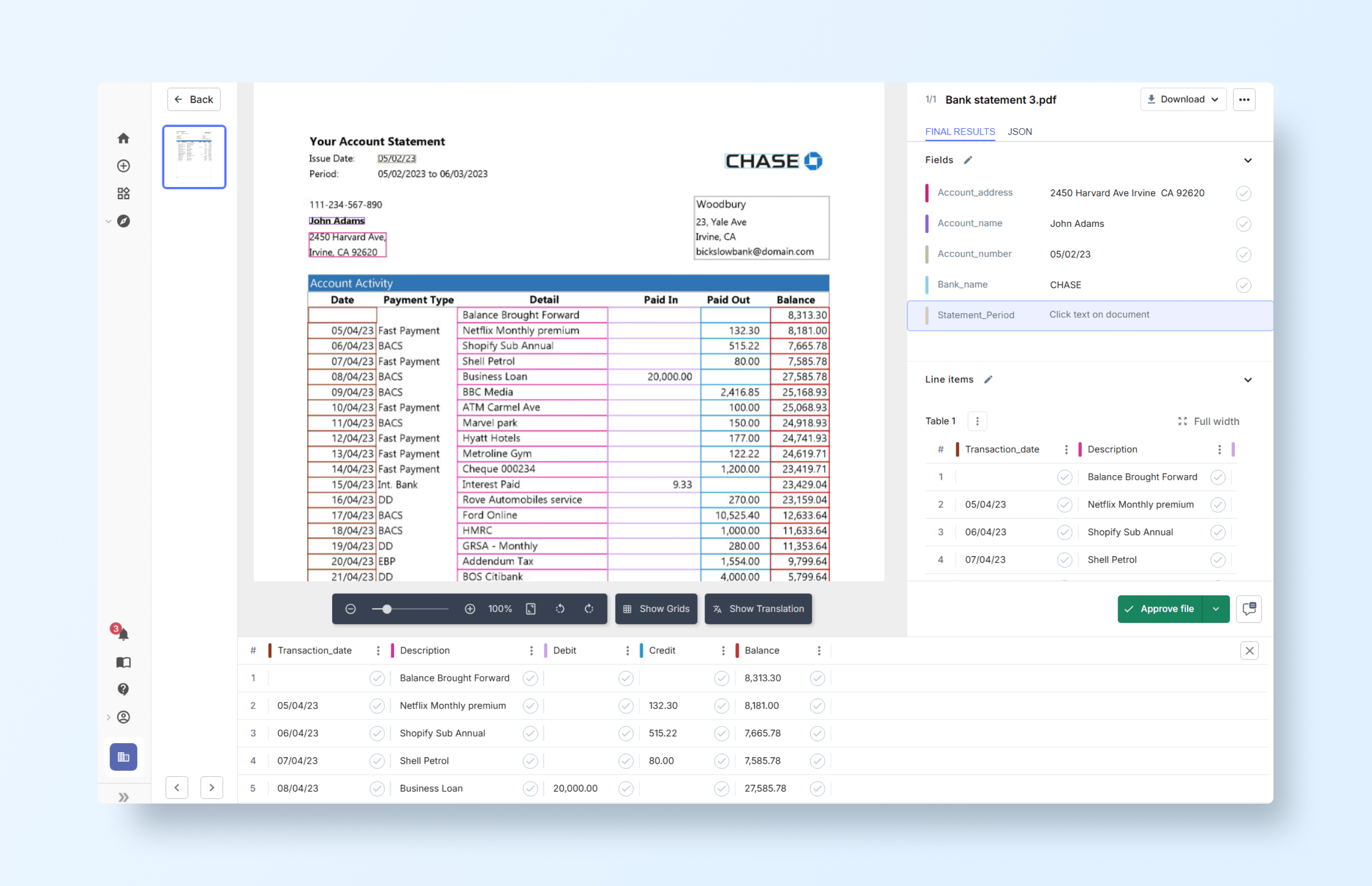
Defining the issue date required manually selecting the text and remapping it from a non-existent ‘account number’ field:
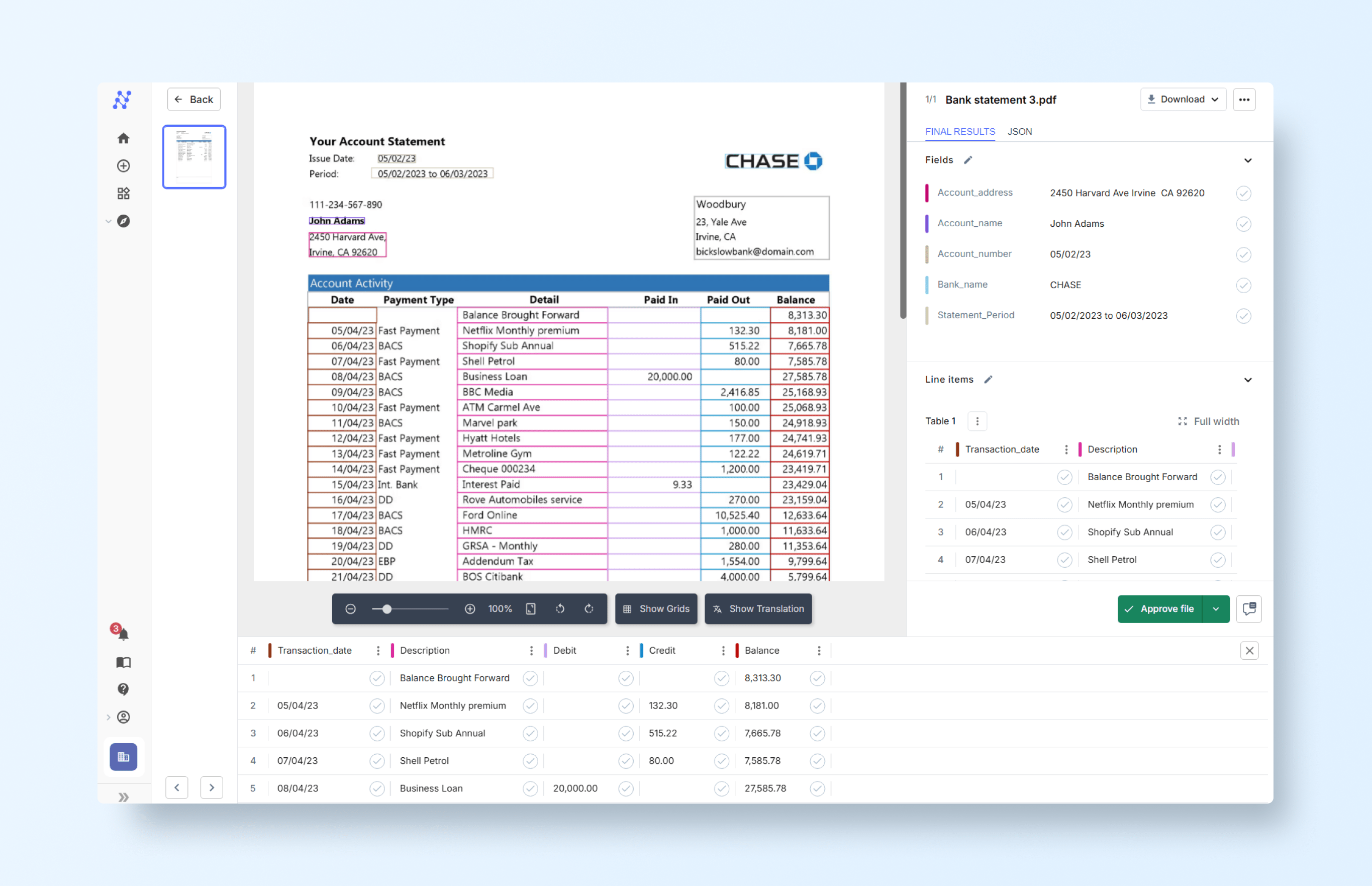
Also adding the statement period:
Automated recognition systems can work, but:
- Automated extraction remains prone to errors that require manual fixes.
- It still misses several fields, meaning new fields must be manually added.
- Even with improved table recognition, the output often requires adjustments.
- Overall, the process remains partially manual and maintenance-heavy.
This process is time-consuming and fragile. A single design change – a new logo, a shifted table, an additional line of text – can break the template entirely, forcing users to reconfigure the system from scratch.
Core Disadvantages of Manual-Template Extraction
Even after years of incremental improvements, template-based extraction remains fragile and inefficient. Below are the core disadvantages that make manual template extraction fundamentally unsustainable:
- Breaks when layouts change: An invoice with a new header or a bank statement with different column spacing often renders existing templates useless.
- Requires continuous manual upkeep: Teams must constantly update templates for each variation, burning time and resources.
- Fails across multiple formats: Scanned PDFs, semi-structured tables, or narrative-style reports all require different handling, making scaling nearly impossible.
- Not scalable: For organizations processing hundreds of vendors, clients, or document types, maintaining templates is a never-ending cycle.
Despite all of this and two decades of “innovation”, manual templates remain the backbone of many document processing tools. They solve the problem only for fixed, repetitive formats, but fall apart when faced with the messy, dynamic reality of real-world documents.
Why Custom Schemas for structured data extraction matter
The concept of a schema is simple but powerful: it is a structured definition of exactly which data fields you want to extract, including their types, constraints, and validation rules. A schema can specify that a field must be a string (e.g., a customer name), a date (e.g., transaction date), a boolean (e.g., “Is Lease Active?”), or a nested JSON object (e.g., a list of transactions). In short, schemas bring structure and reliability to the messy world of unstructured documents.
Why Businesses Need Them
The challenge with real-world documents is that every industry, and often every organization, has its own requirements. Standard invoice fields or receipt totals rarely cover the complexity of business processes. Consider:
- Insurance firms: may need to capture claimant history, policy details, and risk assessment notes from long-form reports.
- Real estate firms: rely on rent-roll metrics, lease terms, square footage, and valuation data, none of which appear in standard templates.
- Banks and financial institutions: often require regulatory-specific transaction details, counterparty identifiers, or audit trails that go well beyond simple balances and totals.
Without customizable schemas, organizations are forced to either (a) manually extract this data, or (b) shoehorn their unique requirements into rigid extraction tools – both inefficient and error-prone.
The Role of Customizable Schemas in unstructured document processing
By allowing businesses to define their own schemas, document processing platforms can:
- Guarantee that the output is structured exactly as required.
- Enforce data validation at the point of extraction (e.g., ensuring dates are properly formatted).
- Provide outputs in machine-readable formats like JSON, ready for downstream analytics or automation.
This is why the ability to extract data using template-free, schema-first AI has become a critical differentiator. Modern organizations are looking for solutions that can deliver JSON output with customizable schemas and provide template-free extraction with full schema flexibility.
In practice, schemas shift the conversation from “what the tool can extract” to “what the business actually needs to extract.”
The AI Breakthrough: Template-Free Document Extraction with LLMs
For years, document extraction meant painstakingly building templates or relying on rigid, pre-built field sets. AI, specifically large language models (LLMs), has fundamentally changed this equation. Instead of being bound to document layouts, extraction can now be driven by language understanding and custom schemas.
How AI-Driven extraction differs from templates
With a traditional system, you upload a document and manually draw boxes or configure positional rules to capture fields. With an LLM-powered system, the process looks entirely different:
- No bounding boxes: You don’t have to map fields to coordinates on a page.
- Schema-first extraction: You define the data structure you want, using a schema with prompts and type hints (e.g., string, date, boolean, JSON).
- Layout-agnostic: Whether the total appears at the top, bottom, or middle of a page doesn’t matter; the model interprets content based on context, not position.
The result is an extraction that is smarter, faster, and resilient to document variation.
Structured Outputs: A New Standard
A key driver of this shift is the ability to produce structured outputs directly from LLMs. Rather than returning raw text or unorganized tables, AI can now generate validated JSON or other structured formats that strictly follow a user-defined schema.
Recent developments underscore this trend: OpenAI introduced structured outputs in its API to enforce JSON formatting; BoundaryML and similar platforms have built frameworks ensuring schema-conformant results; and Hacker News discussions highlight growing developer interest in schema-first extraction approaches that combine LLM flexibility with enterprise-grade reliability.
Together, these advancements move document processing beyond simple OCR into a realm where AI truly understands and structures content.
The Trend: From Templates to AI-Driven Schema
The industry is undergoing a major paradigm shift:
- Old approach: Template-driven OCR + positional rules → fragile, high-maintenance.
- New approach: Schema-driven AI parsing → adaptive, reliable, and business-specific.
This transition unlocks a long-awaited possibility: organizations can finally extract exactly the data they need, in the format they need, without worrying about layouts, templates, or pre-built limitations.
From this:

To this:

Introducing Unstract
After decades of rigid, rule-based systems, the need for a flexible, intelligent approach to document processing has never been clearer. Unstract represents that new generation with a platform built to eliminate both of the legacy bottlenecks that hold businesses back:
- No manual templates.
- Full custom schema support.
Where older systems require bounding boxes and pre-built extractors, Unstract relies entirely on AI-driven schema definitions. Instead of telling the system where to look, you simply tell it what to extract. Unstract interprets the document’s layout, context, and semantics, adapting automatically to variations in design or structure.
Core Capabilities
- Schema definition through prompts: Users define their own schemas using natural language prompts, specifying the fields they want and the output format (for instance, JSON). This creates a flexible yet structured framework that fits each organization’s unique data model.
- Layout-agnostic extraction: Whether processing a bank statement, a rent roll, or a property inspection report, Unstract intelligently understands document content rather than relying on static layouts. A document’s format can change, and Unstract still delivers the correct data, no reconfiguration required.
- Real-time validation and clean JSON output: Every extraction is automatically validated against the user-defined schema. The result is clean, structured JSON data ready for use in analytics pipelines, CRMs, or regulatory systems. All without the need for post-processing or clean up.
Unstract transforms document processing from a maintenance-heavy task into a schema-first, context-aware, AI-driven workflow. It empowers businesses to capture exactly what they need, from any document, in any format, without templates.
Under the Hood: How Unstract Works
Unstract combines AI, structured schemas, and a flexible workflow to turn unstructured documents into validated, machine-readable data. Here’s a closer look at the components that make it possible.
Pre-Processing with LLMWhisperer
Before any extraction occurs, documents, especially scanned PDFs or images, must be converted into a machine-readable format. This is where LLMWhisperer comes in, it processes scanned documents, tables, and free-form text, producing clean text that AI models can interpret.
Using the LLMWhisperer Playground, we can see that output:
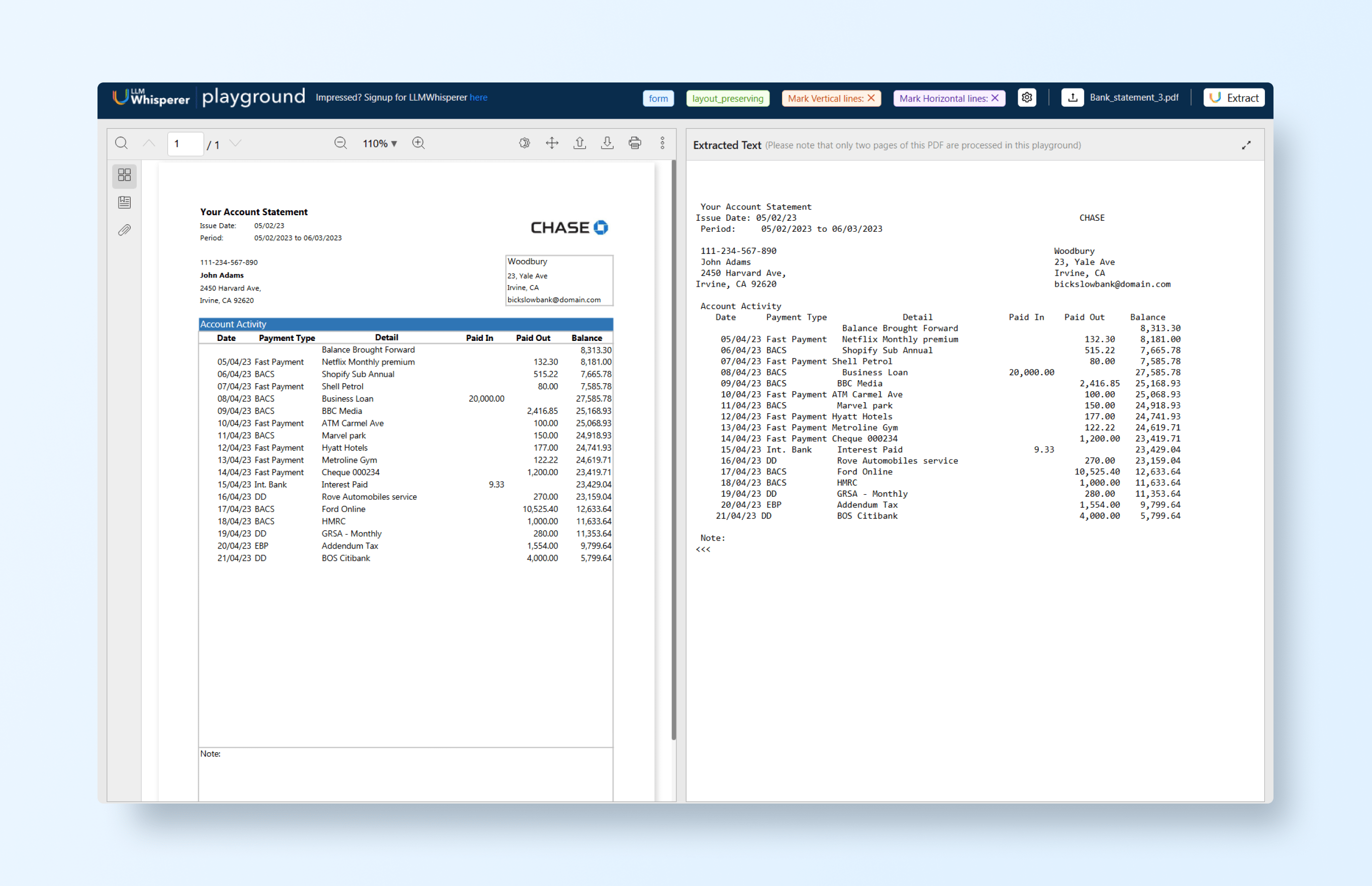
This pre-processing ensures that the downstream extraction model receives structured input rather than messy raw text, improving accuracy and reliability.
Prompt Studio: Defining Custom Schemas
Once the document is pre-processed, Prompt Studio allows users to define custom schemas and write prompts tailored to their business needs.
- Users specify which fields to extract and validation rules.
- Example: A real estate report schema might include:
property_address: stringinspection_date: dateproperty_value: floatinspection_notes: string
With these schemas, the AI model knows exactly what data to find and how to structure it, even if the document layout varies.
Workflow → API Deployment
Once schemas and prompts are defined, Unstract makes it easy to deploy extraction as a scalable API workflow:
- Deploy schema-based extraction as an API: Every request automatically applies the defined schema and returns structured output.
- Test and validate: Using tools like Postman, users can upload a document and immediately receive validated JSON output. The same API can handle new documents with different layouts, no manual template reconfiguration required.
By combining LLMWhisperer for OCR, Prompt Studio for schema definition, and API deployment for integration, Unstract delivers a flexible, intelligent, and fully automated document processing pipeline.
Unstract In Action
Now that we’ve explored the limitations of legacy systems and the power of schema-driven AI, let’s see how Unstract puts these ideas into practice. In the following example, we’ll walk through how Unstract ingests real-world documents, applies schema definitions through prompts, and produces clean, validated JSON output, all without manual templates or rule-based setup.
Getting Started
Unstract’s Prompt Studio offers a no-code workspace for designing and refining AI-powered prompts that convert unstructured documents, such as PDFs, scanned reports, or business statements, into structured, machine-readable data.
In this walkthrough, we’ll use Prompt Studio to define prompts that extract key fields from a real-world example, a bank statement:
To get started, visit the Unstract website and create a free account. The signup process takes just a few minutes and provides access to Unstract’s key tools, including Prompt Studio and LLMWhisperer.
Every new account includes a 14-day trial and 1 million LLM tokens, giving you everything you need to begin building and testing your own document extraction workflows right away.
Setting Up Prompts
Once logged in, open Prompt Studio and create a new project tailored to your document type, for example, a bank statement. Let’s name this project “Bank Analysis”.
Next, navigate to the Manage Documents section to upload the statement you want to process. After uploading, you can begin defining the prompts that specify the key data fields you want to extract, such as account number, statement period, customer name, and transaction details.
Prompts serve as precise instructions for the AI, telling it what to look for and how to structure the extracted data. For instance, here’s an example prompt designed to capture the statement dates section:
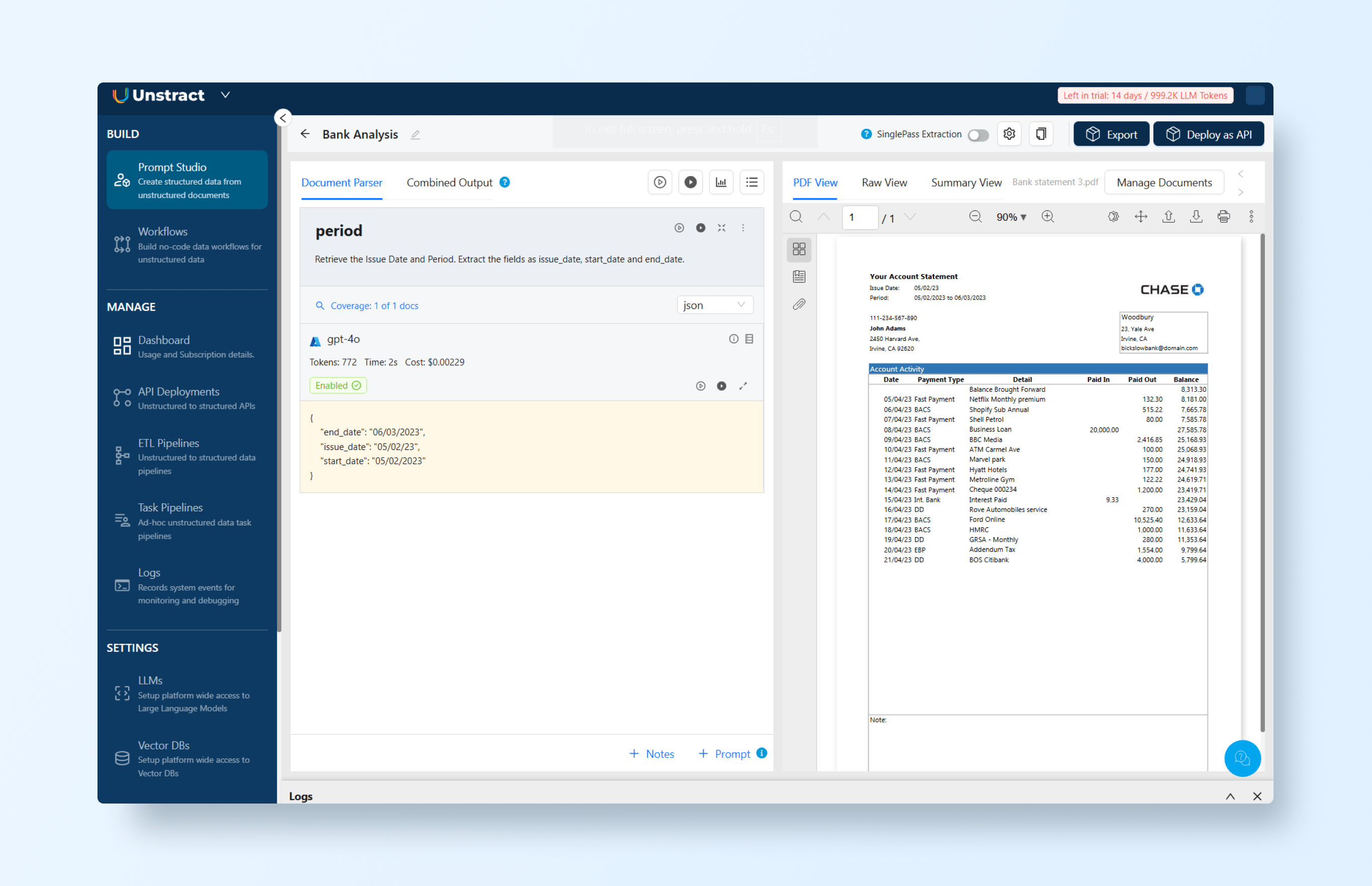
Retrieve the Issue Date and Period. Extract the fields as issue_date, start_date, and end_date.Tip: Always set the output format to JSON to ensure clean, structured results.
When we run this prompt, it returns the following JSON:
And the prompt designed to capture the customer section:
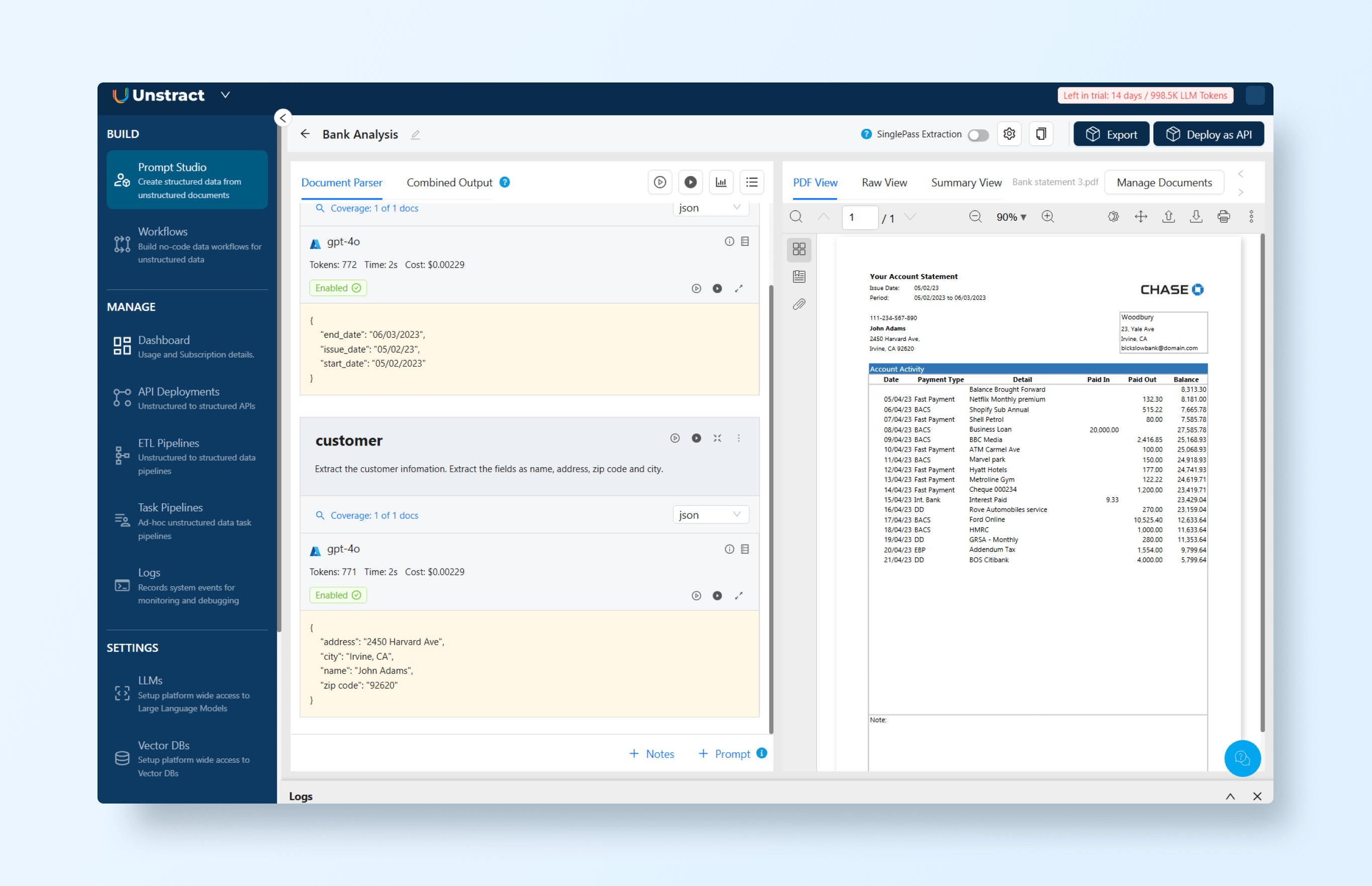
Extract the customer information. Extract the fields as name, address, zip code and city.Note: Set the output format to JSON to ensure properly structured results.
When we run this prompt, it generates the following JSON output:
Finally, let’s define the prompt to extract the statement table details:
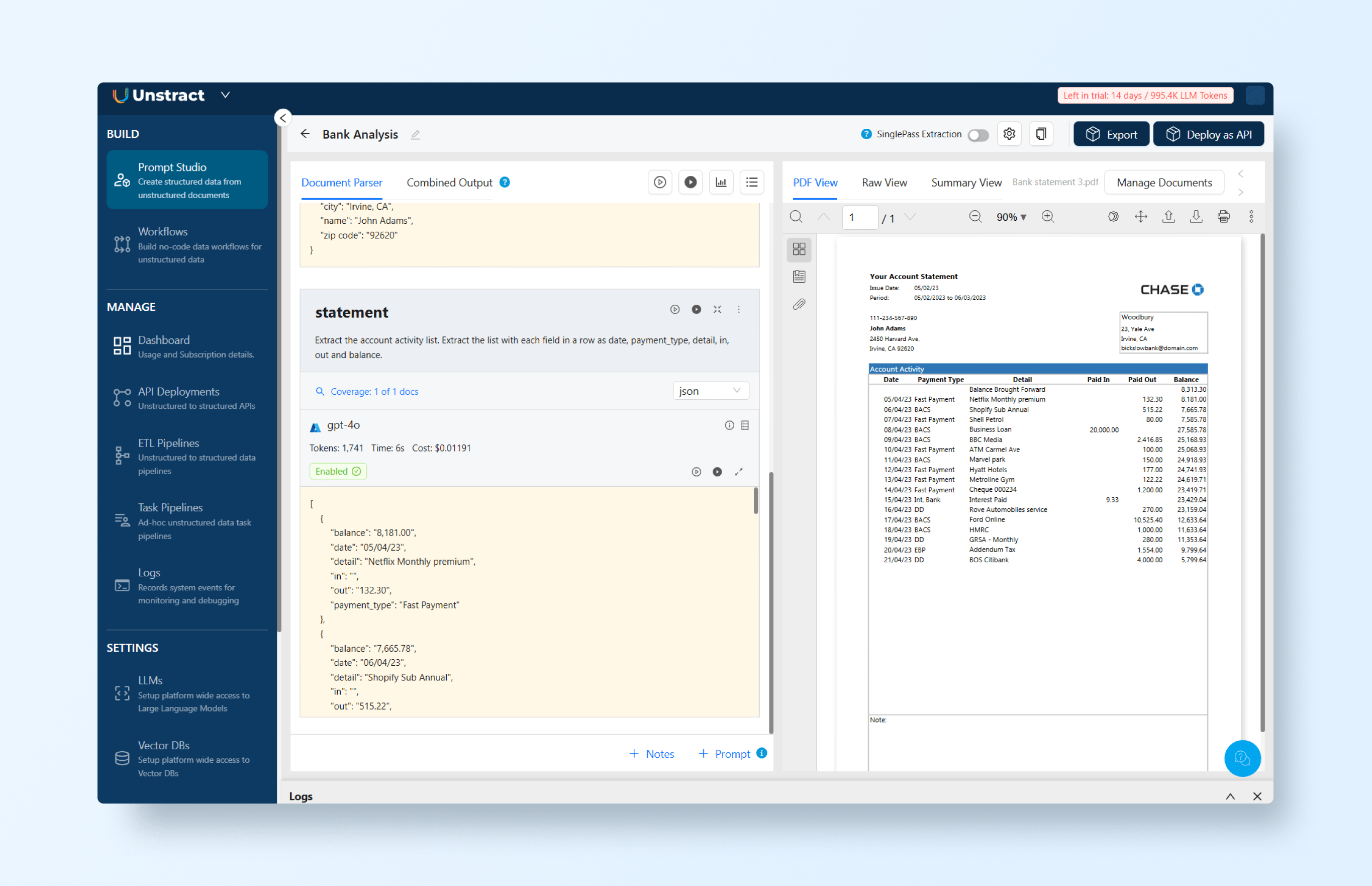
Extract the account activity list. Extract the list with each field in a row as date, payment_type, detail, in, out, and balance.Note: Set the output format to JSON to ensure properly structured results.
This prompt generates the following JSON output:
Combining all the prompts, the full JSON output is:
{
"period": {
"end_date": "06/03/2023",
"issue_date": "05/02/23",
"start_date": "05/02/2023"
},
"customer": {
"address": "2450 Harvard Ave",
"city": "Irvine, CA",
"name": "John Adams",
"zip code": "92620"
},
"statement": [
{
"balance": "8,181.00",
"date": "05/04/23",
"detail": "Netflix Monthly premium",
"in": "",
"out": "132.30",
"payment_type": "Fast Payment"
},
{
"balance": "7,665.78",
"date": "06/04/23",
"detail": "Shopify Sub Annual",
"in": "",
"out": "515.22",
"payment_type": "BACS"
},
{
"balance": "7,585.78",
"date": "07/04/23",
"detail": "Shell Petrol",
"in": "",
"out": "80.00",
"payment_type": "Fast Payment"
},
{
"balance": "27,585.78",
"date": "08/04/23",
"detail": "Business Loan",
"in": "20,000.00",
"out": "",
"payment_type": "BACS"
},
{
"balance": "25,168.93",
"date": "09/04/23",
"detail": "BBC Media",
"in": "",
"out": "2,416.85",
"payment_type": "BACS"
},
{
"balance": "25,068.93",
"date": "10/04/23",
"detail": "ATM Carmel Ave",
"in": "",
"out": "100.00",
"payment_type": "Fast Payment"
},
{
"balance": "24,918.93",
"date": "11/04/23",
"detail": "Marvel park",
"in": "",
"out": "150.00",
"payment_type": "BACS"
},
{
"balance": "24,741.93",
"date": "12/04/23",
"detail": "Hyatt Hotels",
"in": "",
"out": "177.00",
"payment_type": "Fast Payment"
},
{
"balance": "24,619.71",
"date": "13/04/23",
"detail": "Metroline Gym",
"in": "",
"out": "122.22",
"payment_type": "Fast Payment"
},
{
"balance": "23,419.71",
"date": "14/04/23",
"detail": "Cheque 000234",
"in": "",
"out": "1,200.00",
"payment_type": "Fast Payment"
},
{
"balance": "23,429.04",
"date": "15/04/23",
"detail": "Interest Paid",
"in": "9.33",
"out": "",
"payment_type": "Int. Bank"
},
{
"balance": "23,159.04",
"date": "16/04/23",
"detail": "Rove Automobiles service",
"in": "",
"out": "270.00",
"payment_type": "DD"
},
{
"balance": "12,633.64",
"date": "17/04/23",
"detail": "Ford Online",
"in": "",
"out": "10,525.40",
"payment_type": "BACS"
},
{
"balance": "11,633.64",
"date": "18/04/23",
"detail": "HMRC",
"in": "",
"out": "1,000.00",
"payment_type": "BACS"
},
{
"balance": "11,353.64",
"date": "19/04/23",
"detail": "GRSA - Monthly",
"in": "",
"out": "280.00",
"payment_type": "DD"
},
{
"balance": "9,799.64",
"date": "20/04/23",
"detail": "Addendum Tax",
"in": "",
"out": "1,554.00",
"payment_type": "EBP"
},
{
"balance": "5,799.64",
"date": "21/04/23",
"detail": "BOS Citibank",
"in": "",
"out": "4,000.00",
"payment_type": "DD"
}
]
}
Deploying as an API
With your prompts defined and tested, you’re ready to deploy them as an API. This allows you to integrate the extraction pipeline directly into your workflow or test it with tools like Postman.
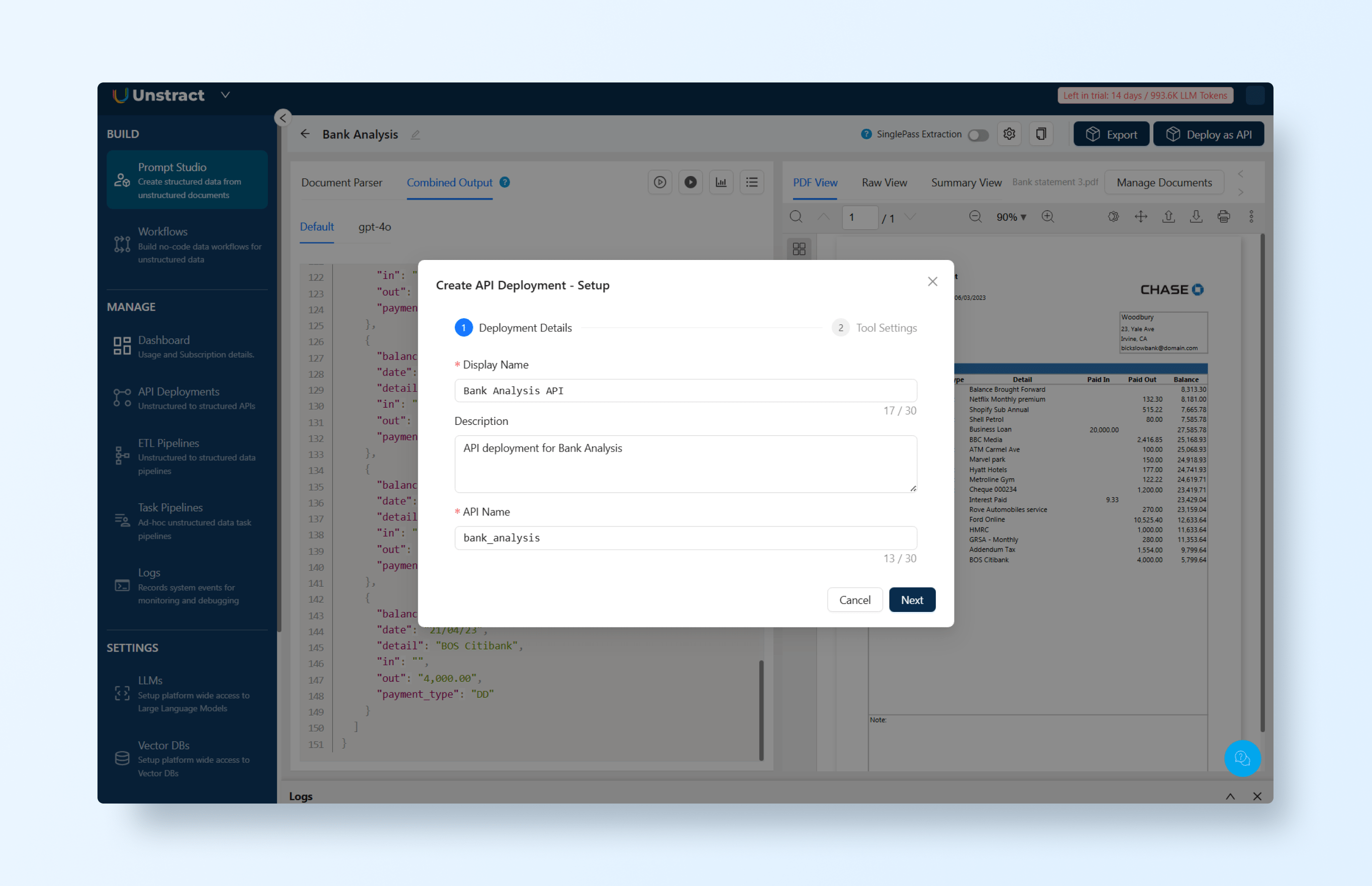
To deploy, simply click the “Deploy as API” button in the top-right corner of Prompt Studio. This will guide you through the deployment flow.
Let’s start by defining a name for the API, like bank_analysis:
On the tool settings, you can leave the default values:
And after a few seconds, your API is deployed:
In the API deployment list, you can access the actions menu and download a Postman collection for testing and/or manage the API keys:
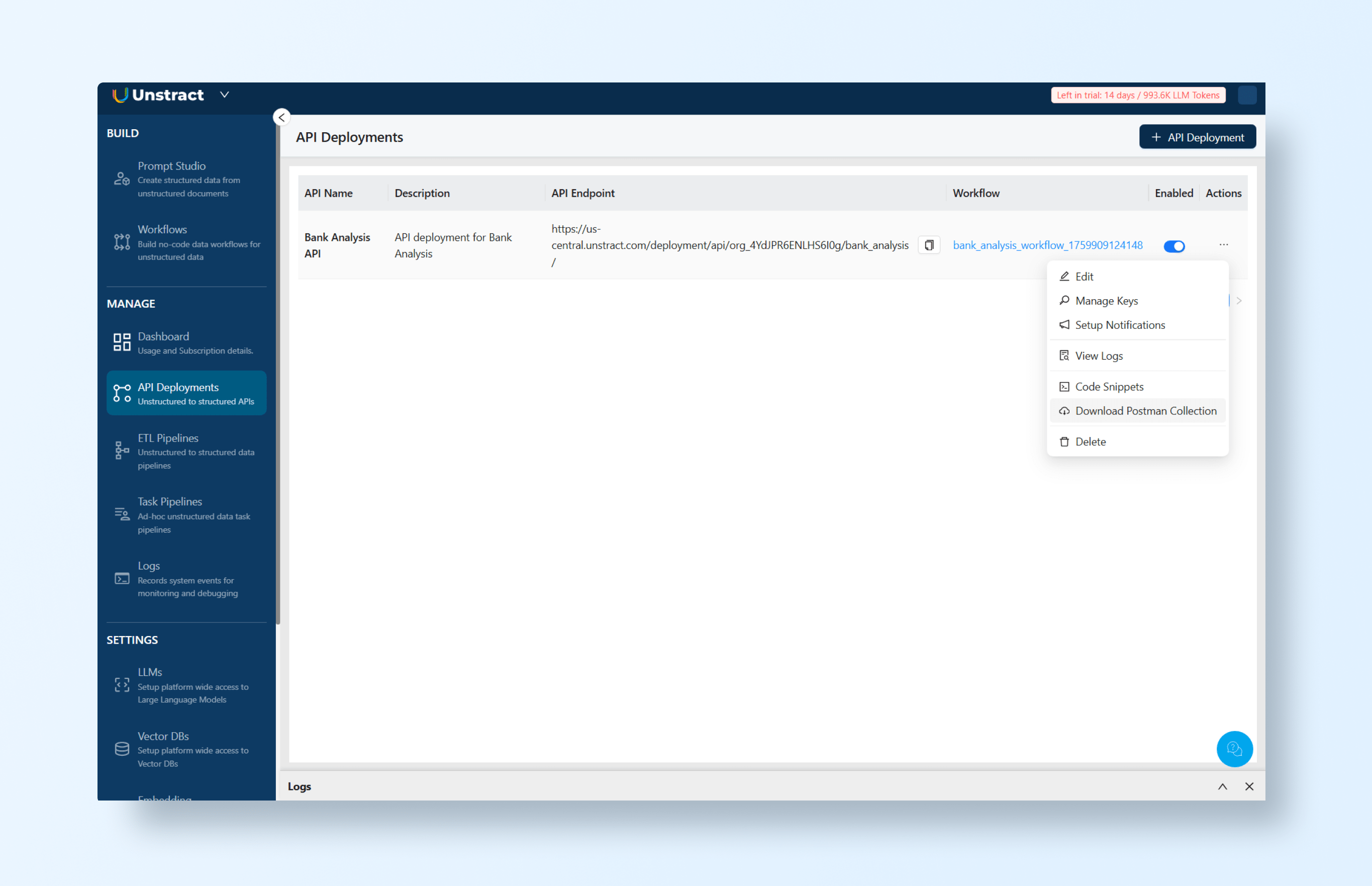
Retrieve the API key with ‘Manage Keys’ and write it down, and also download the Postman collection.
Testing the extraction API with Postman
We can now see how the model adapts seamlessly to a completely different bank statement by testing the deployed API in Postman. This demonstrates Unstract’s ability to handle layout variations without retraining or redefining templates.
First, import the collection into your workspace:
Then configure the authentication with the API key retrieved earlier. Now let’s test the API with another PDF file:
Which produces the output:
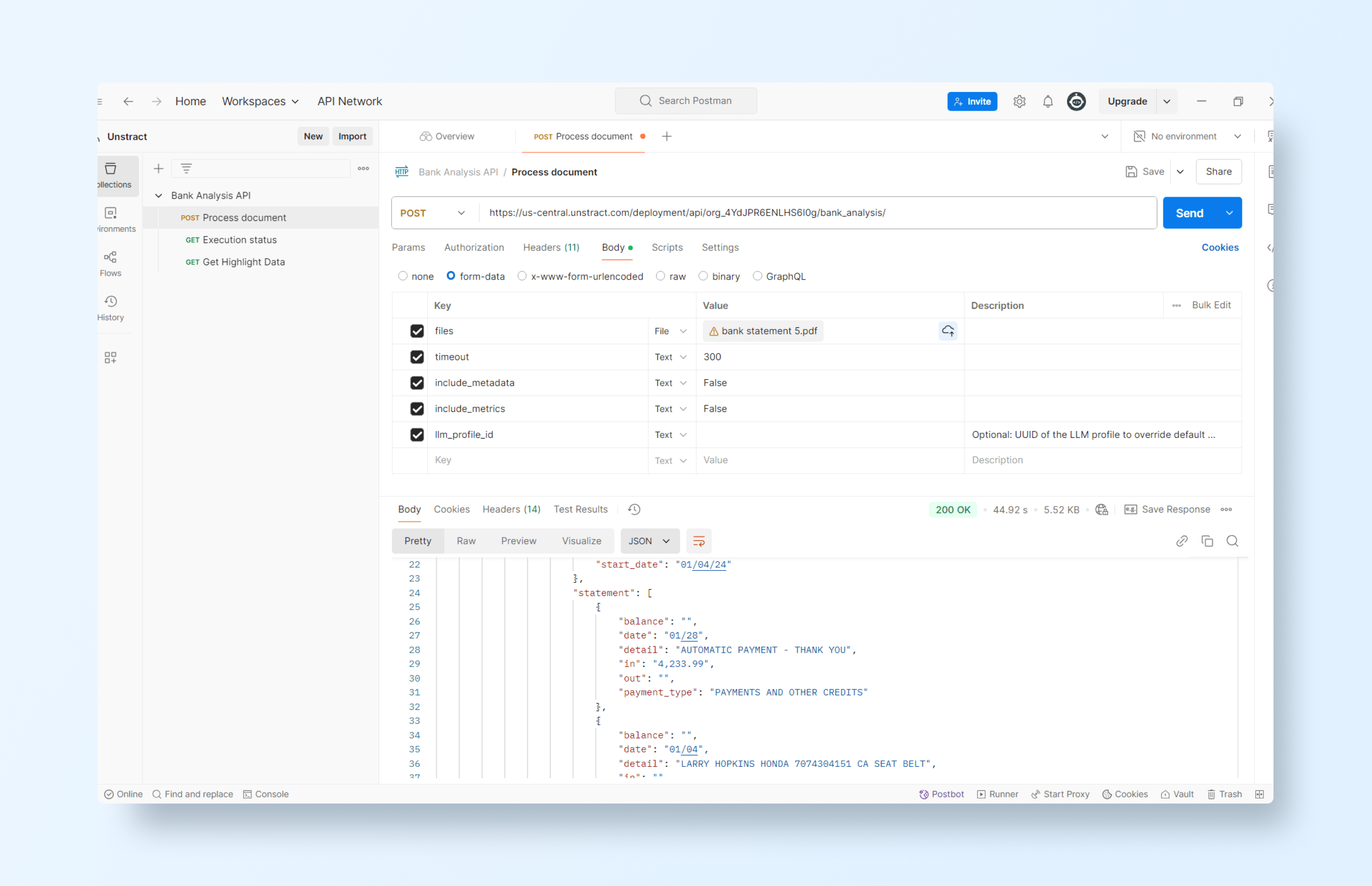
And the corresponding JSON:
{
"message": {
"execution_status": "COMPLETED",
"status_api": "/deployment/api/org_4YdJPR6ENLHS6I0g/bank_analysis/?execution_id=441e11c3-fb52-45c2-a50d-173b873820d1",
"error": null,
"result": [
{
"file": "bank statement 5.pdf",
"file_execution_id": "7a0f6d7b-41bb-4500-bb2d-8e09936c22f8",
"status": "Success",
"result": {
"output": {
"customer": {
"address": "24917 Keystone Ave",
"city": "Los Angeles",
"name": "Larry Page",
"zip code": "97015-5505"
},
"period": {
"end_date": "02/03/24",
"issue_date": "02/03/24",
"start_date": "01/04/24"
},
"statement": [
{
"balance": "",
"date": "01/28",
"detail": "AUTOMATIC PAYMENT - THANK YOU",
"in": "4,233.99",
"out": "",
"payment_type": "PAYMENTS AND OTHER CREDITS"
},
{
"balance": "",
"date": "01/04",
"detail": "LARRY HOPKINS HONDA 7074304151 CA SEAT BELT",
"in": "",
"out": "265.40",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/04",
"detail": "CICEROS PIZZA SAN JOSE CA",
"in": "",
"out": "28.18",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/05",
"detail": "USPS PO 0545640143 LOS ALTOS CA",
"in": "",
"out": "15.60",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/07",
"detail": "TRINETHRA SUPER MARKET CUPERTINO CA",
"in": "",
"out": "7.92",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/04",
"detail": "SPEEDWAY 5447 LOS ALTOS HIL CA",
"in": "",
"out": "31.94",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/06",
"detail": "ATT*BILL PAYMENT 800-288-2020 TX",
"in": "",
"out": "300.29",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/07",
"detail": "AMZN Mktp US*RT4G124P0 Amzn.com/bill WA",
"in": "",
"out": "6.53",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/07",
"detail": "AMZN Mktp US*RT0Y474Q0 Amzn.com/bill WA",
"in": "",
"out": "21.81",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/05",
"detail": "HALAL MEATS SAN JOSE CA",
"in": "",
"out": "24.33",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/09",
"detail": "VIVINT INC/US 800-216-5232 UT",
"in": "",
"out": "52.14",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/09",
"detail": "COSTCO WHSE #0143 MOUNTAIN VIEW CA APPLE TV",
"in": "",
"out": "75.57",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/11",
"detail": "WALGREENS #689 MOUNTAIN VIEW CA",
"in": "",
"out": "18.54",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/12",
"detail": "GOOGLE *YouTubePremium g.co/helppay# CA",
"in": "",
"out": "22.99",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/13",
"detail": "FEDEX789226298200 Collierville TN",
"in": "",
"out": "117.86",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/19",
"detail": "SHELL OIL 57444212500 FREMONT CA",
"in": "",
"out": "7.16",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/19",
"detail": "LEXUS OF FREMONT FREMONT CA",
"in": "",
"out": "936.10",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/19",
"detail": "STARBUCKS STORE 10885 CUPERTINO CA",
"in": "",
"out": "11.30",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/22",
"detail": "TST* CHAAT BHAVAN MOUNTAI MOUNTAIN VIEW CA",
"in": "",
"out": "28.95",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/23",
"detail": "AMZN Mktp US*R06VS6MNO Amzn.com/bill WA",
"in": "",
"out": "7.67",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/23",
"detail": "UALR REMOTE PAY 501-569-3202 AR WEB HOSTING",
"in": "",
"out": "2,163.19",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/23",
"detail": "UALR REMOTE PAY 501-569-3202 AR",
"in": "",
"out": "50.00",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/24",
"detail": "AMZN Mktp US*R02SO5L22 Amzn.com/bill WA",
"in": "",
"out": "8.61",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/24",
"detail": "TIRUPATHI BHIMAS MILPITAS CA",
"in": "",
"out": "58.18",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/25",
"detail": "AMZN Mktp US*R09PP5NE2 Amzn.com/bill WA",
"in": "",
"out": "28.36",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/26",
"detail": "COSTCO WHSE #0143 MOUNTAIN VIEW CA GROCERIES",
"in": "",
"out": "313.61",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/29",
"detail": "AMZN Mktp US*R25221T90 Amzn.com/bill WA",
"in": "",
"out": "8.72",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/29",
"detail": "COMCAST CALIFORNIA 800-COMCAST CA",
"in": "",
"out": "97.00",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/29",
"detail": "TRADER JOE S #127 LOS ALTOS CA",
"in": "",
"out": "20.75",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/30",
"detail": "Netflix 1 8445052993 CA",
"in": "",
"out": "15.49",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/30",
"detail": "ATT*BILL PAYMENT 800-288-2020 TX",
"in": "",
"out": "300.35",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "01/30",
"detail": "APNI MANDI FARMERS MARKE SUNNYVALE CA",
"in": "",
"out": "36.76",
"payment_type": "PURCHASE"
},
{
"balance": "",
"date": "02/01",
"detail": "APPLE.COM/BILL 866-712-7753 CA",
"in": "",
"out": "2.99",
"payment_type": "PURCHASE"
}
]
}
},
"error": null,
"metadata": {
"source_name": "bank statement 5.pdf",
"source_hash": "ee1ca20d96673758b41fc21965374196070d993637a30bf1c3182f045731d12d",
"organization_id": "org_4YdJPR6ENLHS6I0g",
"workflow_id": "df092058-aa3c-46c5-be5d-d324be43b8d7",
"execution_id": "441e11c3-fb52-45c2-a50d-173b873820d1",
"file_execution_id": "7a0f6d7b-41bb-4500-bb2d-8e09936c22f8",
"tags": [],
"total_elapsed_time": 24.018118,
"tool_metadata": [
{
"tool_name": "structure_tool",
"elapsed_time": 24.018112,
"output_type": "JSON"
}
]
}
}
]
}
}
As you can see, even with a completely different layout, Unstract successfully extracted all the specified information, proving its ability to adapt across document variations without any manual reconfiguration.
Why Unstract Stands Out from Legacy Systems
While legacy document processing systems have served businesses for decades, they remain fragile, template-driven, and bound by rigid schemas. Any change in document layout, addition of new fields, or variation in format can break the extraction process, requiring manual intervention and constant upkeep.
Unstract, on the other hand, is adaptive, schema-driven, and flexible. By leveraging AI and prompt-based schema definitions, it handles diverse document types without relying on pre-defined templates. Its intelligent extraction adapts automatically to new layouts, validates data in real-time, and outputs structured results tailored to the user’s needs.
This comparison highlights the difference:
- Manual setup → Prompt-driven extraction
- Layout-specific → Layout-agnostic
- Fixed outputs → Custom schemas
- Breaks with change → Adapts instantly
Unstract transforms document processing from a fragile, maintenance-heavy task into a resilient, automated, and highly customizable workflow, allowing organizations to extract exactly the data they need – without worrying about templates or rigid formats.
Conclusion
The landscape of document processing is undergoing a profound shift. Organizations are moving away from template-based rigidity toward schema-driven intelligence, where AI understands content, adapts to layouts, and delivers validated, structured data.
The key takeaway is clear: businesses no longer need to choose between fragile templates and one-size-fits-all outputs. With schema-first, template-free extraction, organizations can capture exactly the information they need – accurately, efficiently, and at scale.
Explore Unstract to experience how template-free, schema-first document extraction can transform your workflows and unlock truly intelligent document processing.
AI Document Processing, Template-less and with Custom Schema Support: FAQs
What is automated document processing with custom schema, and how does it differ from legacy template-based systems?
Automated document processing with custom schema uses advanced AI to extract specific data fields as defined by the user, rather than relying on rigid, manual templates. Unlike legacy systems that require drawing boxes and creating rules for every document layout, this method allows organizations to define their own custom schemas for extraction, making the process layout-agnostic and highly adaptable.
How does AI document processing with no manual templates and custom schema support benefit my business?
AI document processing with no manual templates and custom schema support eliminates the need for constant template reconfiguration when document formats change. This approach lets businesses specify exactly what data they need, regardless of layout, leading to faster, more reliable, and maintenance-free extraction.
What sets Unstract AI document processing—with no manual templates and custom schema support—apart from other solutions?
Unstract AI document processing features no manual templates and full custom schema support, enabling layout-agnostic extraction powered by schema-driven prompts. This template less AI document processing ensures accurate and validated outputs in formats like JSON, no matter how much the document structure varies.
Why choose template less document processing with custom schema?
A no-template document processing with a custom schema allows organizations to move beyond fragile, maintenance-heavy templates. With this approach, you define what to extract through a schema, rather than how or where, making data extraction resilient to any design or format changes in your documents.
What are the advantages of document processing with no templates and custom schema over traditional template-based extraction?
Document processing with no templates and a custom schema provides significant advantages: it is more scalable, reduces manual effort, and adapts instantly to document changes. This means businesses can automate extraction for any document type—without being limited by pre-built fields or template rigidity.






















