High Accuracy OCR in 2026: Why LLMWhisperer is the Most Accurate OCR
Table of Contents
Introduction: Why high accuracy OCR is critical for businesses
In today’s digital age, businesses rely heavily on document processing for various operations, from financial transactions to legal compliance. However, most business-critical documents exist in unstructured formats such as PDFs, scanned images, and handwritten notes. Extracting valuable data from these documents manually is time-consuming, error-prone, and inefficient. This is where Optical Character Recognition (OCR) plays a crucial role, automating text extraction to streamline workflows across industries.
Importance of OCR Accuracy in Document-Heavy Industries
Several industries depend on OCR technology to handle large volumes of documents efficiently:
Finance & Banking: OCR helps extract information from invoices, receipts, and financial statements to ensure seamless reconciliation and compliance.
Healthcare: Medical records, prescriptions, and insurance claims require precise data extraction to improve patient care and billing accuracy.
Legal & Compliance: Law firms and corporate legal teams process contracts, agreements, and regulatory documents, where errors in data extraction can lead to compliance risks.
Logistics & Supply Chain: Bills of lading, shipping labels, and inventory reports must be digitized accurately for smooth logistics management.
Government & Public Sector: Digitizing tax forms, ID documents, and census records requires high-accuracy OCR to reduce manual processing errors.
Challenges Businesses Face with Traditional OCR Solutions
Despite the widespread adoption of OCR technology, traditional OCR solutions often fall short in accuracy and layout preservation due to:
Low Accuracy in Text Recognition: Poor scan quality, faded text, and handwritten elements reduce OCR precision, leading to errors in extracted data.
Loss of Document Formatting: Complex layouts, multi-column text, and tabular data are often distorted, making the extracted information difficult to interpret.
Inability to Handle Forms & Checkboxes: Traditional OCR struggles with extracting checkbox selections, radio buttons, and form fields, causing data inconsistencies.
Poor Performance on Skewed or Photographed Documents: OCR tools often fail to process documents that are tilted, misaligned, or captured using mobile cameras.
Inefficiency in Large-Scale Document Processing: High latency and lack of automation in OCR pipelines slow down workflows, impacting business productivity.
The Need for High-Accuracy OCR for Document Processing
To overcome these limitations, businesses need high-accuracy OCR solutions that ensure:
Layout Preservation: Extracted text should maintain the document’s original structure, including tables, sections, and formatting.
Support for Complex Documents: The ability to process scanned forms, handwritten documents, and multi-column PDFs with precision.
Handling of Forms & Structured Data: Accurate extraction of checkboxes, form fields, and radio buttons for data integrity.
Scalability & Efficiency: A solution that processes large document batches without compromising speed or accuracy.
LLMWhisperer addresses these challenges by providing high-precision OCR with layout preservation, making document extraction seamless, efficient, and scalable for businesses.
What is LLMWhisperer?
LLMWhisperer API: Fast and accurate OCR for all kinds of documents
Overview of LLMWhisperer and Its Role in OCR Accuracy
LLMWhisperer is an advanced OCR-based document parsing tool designed to extract text from PDFs and scanned images while preserving the document’s original structure. Unlike traditional OCR, LLMWhisperer ensures high accuracy in text recognition and maintains layout integrity, making it ideal for processing complex documents.
It is not an AI-powered or LLM-based tool—instead, it functions as a high-precision PDF parser that extracts data in a format optimized for downstream processing.
How LLMWhisperer Enhances OCR Accuracy
LLMWhisperer improves OCR-based document extraction in the following ways:
Layout Preservation Mode: Unlike conventional OCR tools that extract plain text, LLMWhisperer retains formatting elements such as tables, paragraphs, and columns.
Checkbox & Radio Button Recognition: It accurately detects form elements, ensuring extracted data reflects the original document’s selections.
Auto Mode Switching: If direct text extraction is insufficient, LLMWhisperer automatically switches to OCR mode for enhanced accuracy.
Preprocessing for Image Optimization: Features such as Gaussian Blur, Median Filtering, and Contrast Adjustments improve text clarity in scanned documents.
Auto-Compaction: It reduces unnecessary token usage, optimizing document processing costs while maintaining essential data.
LLMWhisperer is available as a SaaS platform for cloud-based processing and can also be deployed on-premise for businesses requiring data security and compliance.
Document OCR accuracy at the cutting edge: LLMs vs LLMWhisperer
LLMs have become operational powerhouses, thanks in part to their ability to extract rich, meaningful information from documents. But even the best models, in real-world use cases, often depend heavily on the quality of the input they receive.
Discover how LLMWhisperer, Unstract’s dedicated text extraction service, prepares documents for peak LLM performance and sets standards for LLM-ready outputs.
Key Features of LLMWhisperer
LLMWhisperer is designed to address the shortcomings of traditional OCR solutions by offering high-accuracy document parsing with advanced layout preservation, multi-format support, and multilingual capabilities. Below are the key features that make LLMWhisperer a powerful OCR document extraction tool.
Layout Preservation & Why It Matters
One of the biggest challenges in OCR-based document extraction is maintaining the original structure of documents. Traditional OCR tools often extract raw text but fail to retain document elements such as tables, paragraphs, sections, and forms.
With LLMWhisperer’s layout-preserving mode, businesses can:
Extract structured data without losing tabular or multi-column formatting.
Maintain paragraph breaks, bullet points, and lists as they appear in the document.
Ensure contract agreements, invoices, and purchase orders retain their original structure for easier downstream processing.
Improve data readability and usability for integration into business applications.
For example, a financial institution processing scanned invoices with complex line items can use LLMWhisperer to extract the details without breaking the table structure—something traditional OCR solutions struggle with.
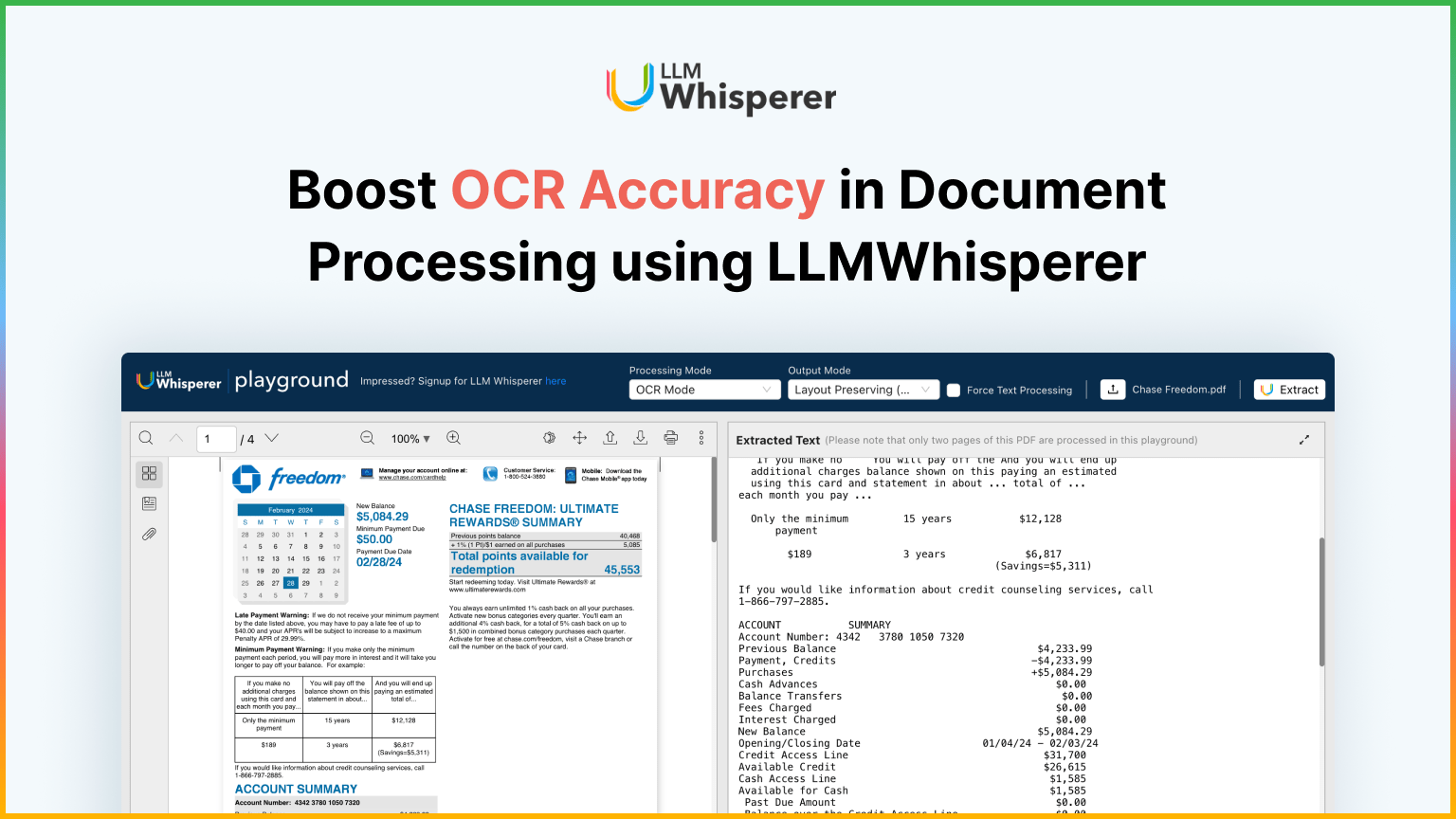
LLMWhisperer: Boosting the accuracy of OCR by preserving the document layout
Supported Document Formats & Types
LLMWhisperer supports a wide range of document formats, making it a versatile OCR tool for various industries.
Standard PDFs – Native text PDFs with selectable text.
Scanned Documents – Extract text from images and scanned PDFs.
Handwritten Documents – Advanced recognition for handwritten notes, signatures, and annotations.
Complex Forms with Checkboxes & Radio Buttons – Accurately detects form selections, ensuring complete data extraction.
Multi-Column Documents – Preserves text alignment and layout for structured reading.
Photographed Documents – Processes documents captured using mobile cameras or scanners, even if skewed or misaligned.
By supporting diverse file types and structures, LLMWhisperer ensures that businesses can digitize and process any document efficiently.
Multi-Lingual OCR Support
A major limitation of traditional OCR tools is their inability to process multiple languages accurately. LLMWhisperer overcomes this by offering support for over 300 languages, making it a powerful tool for global businesses.
Key Capabilities of LLMWhisperer’s Multi-Lingual OCR:
Recognizes and extracts text from documents written in multiple languages.
Supports language detection and mixed-language content
Handles non-Latin scripts, including Arabic, Chinese, Japanese, Cyrillic, and Hindi.
Enhances cross-border document processing for finance, healthcare, and legal industries.
For example, a multinational supply chain company dealing with contracts in Spanish, German, and Mandarin can rely on LLMWhisperer for precise extraction across different languages.
With these features, LLMWhisperer ensures businesses can handle any document processing challenge with unmatched accuracy and efficiency.
LLMWhisperer: A general-purpose PDF-to-text converter service from Unstract.
LLMs are powerful, but their output is as good as the input you provide. LLMWhisperer is a technology that presents data from complex documents (different designs and formats) to LLMs in a way that they can best understand.
If you want to quickly test LLMWhisperer with your own documents, you can check our free playground. Alternatively, you can sign up for our free trial which allows you to process up to 100 pages a day for free.
LLMWhisperer: High accuracy OCR for LLMs
Common Document Use Cases: Where Traditional OCR Fails & How LLMWhisperer Excels
Even with advancements in OCR technology, traditional OCR solutions often fail to extract data accurately from complex documents. Issues such as formatting loss, misaligned text, and missing key elements make data extraction inefficient and error-prone.
LLMWhisperer overcomes these challenges by offering layout-preserving OCR, handwriting recognition, and plain text with preserved visual structure—ensuring high-accuracy document parsing across various industries.
In this section, we explore six real-world scenarios where traditional OCR struggles and demonstrate how LLMWhisperer significantly enhances accuracy and layout integrity.
Each use case will highlight:
Challenges faced by traditional OCR tools – What makes these documents difficult to process?
Why these document types are complex – Structural, handwritten, or low-quality scan issues.
How LLMWhisperer delivers superior results – Leveraging Playground (real-time OCR extraction) or API (batch processing and enterprise integration) for high-accuracy data extraction.
Whether dealing with forms, scanned receipts, handwritten contracts, or financial reports with complex tables, LLMWhisperer provides the precision businesses need to digitize and automate document processing effortlessly.
Now, let’s dive into each challenging document type and see how LLMWhisperer transforms OCR accuracy.
OCR Accuracy Use Case 1: Extracting Data from a Uniform Residential Loan Application with LLMWhisperer
The Challenge: Why Traditional OCR Fails
A Uniform Residential Loan Application is a highly structured financial document that contains:
Blank fields that need to be captured accurately.
Checkboxes for citizenship, marital status, and credit type.
Sectional data formatted into multiple columns, making extraction complex.
Multi-data in a single line (e.g., phone numbers, addresses, income breakdowns).
Tables with financial figures, which must be preserved for correct data interpretation.
Traditional OCR solutions often struggle with retaining layout integrity, especially when extracting data from multi-column structured documents like this. They tend to:
Flatten the text, losing sectional data and hierarchical structure.
Extract checkboxes inaccurately, making it hard to differentiate between selected and unselected options.
Misalign data in tables and structured fields, leading to incomplete or unusable extracted data.
Lose context in multi-data lines, resulting in fragmented and disorganized information.
These challenges make manual data entry unavoidable, slowing down document processing for lenders, financial institutions, and compliance teams.
The Solution: Using LLMWhisperer for High-Accuracy OCR Extraction
To demonstrate LLMWhisperer’s high-accuracy OCR capabilities, we uploaded the Uniform Residential Loan Application to the LLMWhisperer Playground.
No data loss – Every single piece of information is extracted without omissions.
Checkbox recognition – Selected and unselected checkboxes are accurately differentiated.
Financial figures preserved – Monthly income breakdown, rent payments, and ownership details are structured perfectly.
Clear hierarchy and structured sections – Personal information, employment details, and income sources are neatly separated, just as they appear in the original document.
OCR Accuracy Use Case 2: Extracting Data from a Handwritten, Photographed Tax Form Using LLMWhisperer
The Document: Annual Return Plan (Handwritten Tax Form, Photographed)
This document is a Form 5500-EZ (Annual Return Plan) that includes:
Handwritten entries for employer details, EIN, plan numbers, financial figures, and participant data.
Multi-column layout with structured financial information.
Scattered handwritten elements, such as a form number positioned outside the main form layout.
Checkboxes and structured fields, which require precise extraction.
The Result: Perfect Extraction Without Data Loss
After uploading the handwritten tax form to the LLMWhisperer Playground, the extraction results were highly accurate:
Flawless handwritten text recognition, even for numbers and form identifiers.
Zero data loss—every section, including employer details, EIN, and financial assets, was extracted accurately.
Structured multi-column preservation—participant counts, financials, and plan details retained their correct positions.
Checkbox detection—correctly identified plan type and filing status selections.
This proves that LLMWhisperer handles handwritten, photographed documents with precision, ensuring accurate extraction for financial and tax-related data processing.
OCR Accuracy Use Case 3: Extracting Data from a Fully Handwritten Document Using LLMWhisperer API
The Document: Fully Handwritten Text Document
This test involves a completely handwritten document, uploaded via LLMWhisperer API instead of the Playground. The document presents several challenges for OCR, including:
Handwritten words and numbers, varying in clarity and style.
No printed text, meaning standard OCR engines struggle with recognition.
Testing LLMWhisperer API for Handwritten Text Extraction
To process the document using LLMWhisperer API:
Open Postman and create a new POST request.
Set the Request Type to POST.
Use the API URL: https://llmwhisperer-api.us-central.unstract.com/api/v2/whisper
Go to the Headers tab and add:
Key: unstract-key
Value:(Paste your API Key here)
In the Body tab, select binary and upload the handwritten document.
Click Send to initiate the request.
The Result: API-Based Handwriting Recognition with Unmatched Accuracy
Upon retrieval of the extracted data:
Handwritten words were recognized with high precision, even with varied handwriting styles.
Numbers, dates, and critical details were extracted without errors.
Consistent accuracy—the extraction closely matched the handwritten content, ensuring zero data loss.
OCR Accuracy Use Case 4: Extracting Data from a Poorly Aligned or Skewed Photographed Receipt Using LLMWhisperer API
The Document: Tilted, Faded, and Skewed Receipt Image
For this test, we used a photographed receipt that was:
Tilted at approximately 30 degrees, creating a challenge for traditional OCR tools.
Slightly faded and dull, making text recognition harder.
Contains structured data, including itemized billing, tax summary, and payment details.
The Result: Near-Perfect OCR Accuracy Despite Skewed and Faded Text
All receipt details were extracted flawlessly—even with heavy skew and faded text.
Structured data (invoice number, date, cashier name, items, total amount, GST summary, and payment details) was perfectly preserved.
No missing details—every item, including discounts, tax rates, and store information, was extracted accurately.
Correct alignment of text output, ensuring it remains usable for expense tracking, reconciliation, or automated processing.
This proves that LLMWhisperer can handle even poorly aligned, tilted, and low-quality scanned receipts with outstanding accuracy. Businesses can automate receipt processing without worrying about OCR failures due to document misalignment or fading.
OCR Accuracy Use Case 5: Extracting Data from a Hotel Receipt with Handwritten Elements Using LLMWhisperer Playground
The Document: Aged, Dark, and Partially Handwritten Hotel Receipt
For this test, we uploaded an old, slightly faded hotel receipt into the LLMWhisperer Playground to evaluate its OCR accuracy. Key challenges in this document include:
Handwritten guest details (name and room number).
Darkened and aged paper, making text recognition difficult.
Complex layout with mixed printed and handwritten text, service charges, tax breakdowns, and disclaimers.
The Result: Highly Accurate OCR with Full Layout Preservation
Every detail was extracted flawlessly, including printed text, handwritten guest name, and room number.
Layout was perfectly preserved, maintaining structured data for charges, tax calculations, and service details.
No missing elements—even small text such as the GSTIN number, FSSAI registration, and disclaimers were captured.
Handwritten text (Simon Dawes and Room No. A52) was accurately detected, proving LLMWhisperer’s ability to handle mixed-format documents.
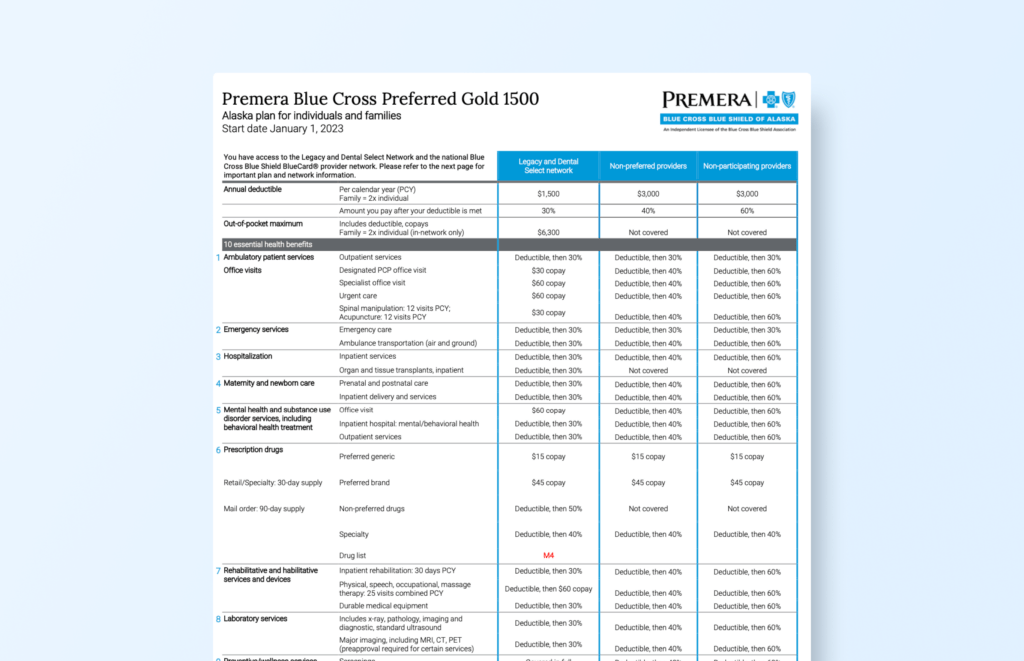
OCR Accuracy Use Case 6: Extracting Data from an Insurance Plan Document with Complex Table Layouts and Dense Text Using LLMWhisperer API
The Document: Highly Structured Insurance Plan with Complex Tables & Small Font
For this test, we uploaded an insurance plan document containing intricate tabular data, dense text, and small fonts into the LLMWhisperer API. Key challenges in this document include:
Multi-row and multi-column table structures with nested sections.
Dense content with small font size, making text recognition difficult.
Financial data, policy numbers, and detailed plan breakdowns embedded within tables.
The Result: Accurate Extraction with Full Table & Text Preservation
Complex tables extracted with structure intact, keeping rows and columns well-aligned.
Policy details, financial terms, and benefit breakdowns were accurately captured.
There is no loss of data despite the small font size and dense text formatting.
Table formatting is maintained, ensuring numerical values and plan descriptions are properly organized.
Not Magic—Just LLMWhisperer’s Superior OCR Capabilities.
Even with complex multi-column tables and intricate layouts, LLMWhisperer accurately extracted and structured every detail. This proves its unmatched capability to process dense insurance documents, financial reports, and policy agree.
Conclusion: Why Businesses Should Use LLMWhisperer for High-Accuracy OCR
In today’s data-driven world, businesses rely on accurate document processing to streamline operations, improve compliance, and enhance decision-making. Traditional OCR solutions often struggle with complex layouts, multi-column data, handwritten content, and structured tables, leading to inaccurate data extraction and formatting loss. LLMWhisperer changes the game by offering high-precision OCR designed for real-world business needs.
Why LLMWhisperer is the Best Choice for OCR Accuracy
Handles Complex Documents with Precision Unlike standard OCR tools, LLMWhisperer preserves layout structures, ensuring tables, sections, and line items remain intact. Whether it’s legal contracts, invoices, tax forms, or financial reports, the tool extracts data without disrupting its original formatting.
Supports a Wide Range of Documents LLMWhisperer processes scanned PDFs, photographed receipts, structured business forms, handwritten records, and multi-column reports with ease. It also recognizes checkboxes, radio buttons, and handwritten text—a major advantage over conventional OCR tools.
Advanced Multi-Lingual OCR Capabilities Supporting over 300+ languages, LLMWhisperer is the perfect choice for global businesses handling multilingual documentation, ensuring accurate extraction across different regions and industries.
Available in Two Flexible Modes: Playground & API Businesses can use LLMWhisperer in two ways, depending on their requirements:
Playground – A no-code, web-based interface for quick document testing and real-time OCR extraction.
API Integration – Ideal for batch processing and enterprise automation, allowing seamless integration into ERP, CRM, and document management systems.
Get Started with LLMWhisperer Today!
The accuracy and efficiency of document processing directly impact business performance. With LLMWhisperer, companies can reduce manual errors, accelerate workflows, and extract structured data with near-perfect precision.
Try it for free today:
Test in Playground – Upload your documents and see the real-time extraction in action.
Integrate via API – Automate your document processing workflow effortlessly.
If you want to quickly take it for a test drive, sign up for a free trial. Process up to 100 pages a day completely free! No credit card required.
1. Why should my business invest in high accuracy ocr instead of traditional OCR?
High accuracy OCR with LLMWhisperer preserves document layouts, correctly extracts checkboxes and handwritten notes, and works on skewed or faded scans. This eliminates manual data entry, reduces errors, and accelerates workflows in finance, healthcare, legal, and logistics.
2. Which industries benefit most from the most accurate ocr software?
The most accurate OCR software is critical for finance (invoices, statements), healthcare (medical records, prescriptions), legal (contracts), logistics (bills of lading), and government (tax forms). LLMWhisperer’s layout preservation ensures data integrity in all these sectors.
3. How does accurate ocr software improve compliance and audit readiness?
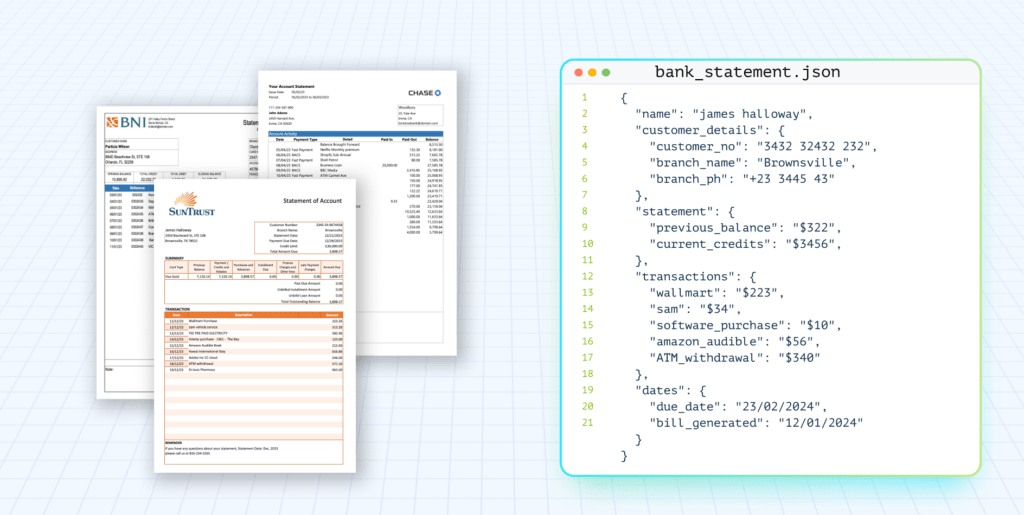
Accurate OCR software like LLMWhisperer extracts every field, table, and checkbox exactly as it appears in the original document. This creates an auditable, structured output (JSON, CSV, Excel) that supports regulatory reporting, contract compliance, and financial reconciliation.
4. Can LLMWhisperer be used as accurate ocr for handwritten and photographed tax forms?
Yes. The blog demonstrates accurate OCR on a handwritten, photographed Form 5500‑EZ. LLMWhisperer captured employer details, EIN, plan numbers, financial figures, and checkboxes with zero data loss — even when the form number was placed outside the main layout.
5. What is the business case for choosing LLMWhisperer as most accurate ocr software over alternatives?
LLMWhisperer offers a free Playground (no‑code testing), a pay‑per‑page API, and on‑premise deployment for sensitive data. As most accurate OCR software, it reduces downstream manual correction costs, speeds up batch processing, and integrates with ERPs and CRMs.
6. How does high accuracy ocr impact customer experience and operational speed?
High accuracy OCR enables same‑day processing of loan applications, claim forms, and purchase orders. By automating data extraction from complex or poorly aligned documents, businesses cut turnaround times from days to minutes, improving customer satisfaction and retention.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Engineer by trade, creator at heart, I blend Python, ML, and LLMs to push the boundaries of AI—combining deep learning and prompt engineering with a passion for storytelling. As an author of books and articles on tech, I love making complex ideas accessible and unlocking new possibilities at the intersection of code and creativity.